 IST,
IST,




Forecasting Food Inflation using News-based Sentiment Indicators
Bhanu Pratap, Abhishek Ranjan, Vimal Kishore and Binod B. Bhoi* Received on: June 1, 2022 Combining high frequency information on prices with market intelligence on highimpact food items helps nowcast food inflation and generate near-term inflation forecasts. Three key vegetables viz., tomatoes, onions and potatoes (TOP), with a combined weight of 2.2 per cent in the consumer price index (CPI) basket in India, however, contribute heavily to volatility in both food inflation and headline inflation, impacting the performance of nowcasts. Using big data techniques and information on these three items reported in nine leading English news dailies published during 2011-2021, this paper constructs commodity sentiment indices to capture price dynamics of TOP commodities. Empirical findings suggest an inverse relationship between the constructed news sentiment indices of TOP and changes in TOP prices. Exploiting this feature in a formal forecasting framework to predict inflation in vegetables and food prices, it is found that adding news-based information in the form of net sentiments improves forecasting accuracy. JEL: C22, C32, C45, C55, E31, E37 Keywords: Inflation, big data, news sentiment, time-series, forecasting Introduction Under the flexible inflation targeting (FIT) framework introduced in India in 2016, inflation target is defined as 4 per cent CPI headline inflationwith a tolerance band of ± 2 per cent around the target1. While the monetary policy committee (MPC) is entrusted with the task of maintaining headline inflation around this target, the high share of food and beverages in the CPI basket along with its high price volatility driven by recurrent supply shocks often complicates this task besides exposing inflation forecasts to greater uncertainty. Tomatoes, onions and potatoes (TOP), the three main vegetables that are produced and consumed widely in the country form an integral part of the Indian diet, so much so that they are hard to substitute. India also happens to be the second largest producer of these vegetables after China besides beingamongst the major consumers in the world2. However, the indispensable nature of these items gives rise to a major problem for households as well as for generating reliable inflation forecasts, which serve as the intermediate target for monetary policy under inflation targeting. High volatility in TOP prices, often caused by crop damages on account of the vagaries of nature (excess or deficient rainfall and other extreme weather events) lead to production shortfalls, pushing up food inflation as well as headline inflation. Extreme weather events driven by climate change also made the task of forecasting inflation quite challenging in the last few years (Ghosh et al., 2021) such that augmenting models with information on extreme weather events can improve forecasting performance (Kishore and Shekhar, 2022 forthcoming). The Reserve Bank of India (RBI) also noted that “in a rapidly changing scenario where volatility in prices of key vegetables has substantial fallout on headline inflation, there is a need for real time monitoring of price situation, especially in case of perishables” (RBI, 2021). This underscores the need for exploring alternative sources of information that can be useful for forecasting food inflation in India. In this context, newspaper articles about crop damages, extreme weather events, pest attacks, trade restrictions, transporters’ strikes or other adverse events - which can have a significant impact on future prices - can provide useful additional information. The sentiment associated with each article and the coverage frequency of these events can provide helpful information regarding such price shocks. This forward-looking information can be extracted and analysed using text mining analysis. Current developments in natural language processing (NLP) help in quantifying such information, which can then be used in forecasting models to make more accurate predictions about the variables of interest (Shapiro et al., 2020; Kalamara et al., 2020; Barbaglia et al., 2022). Keeping this in mind, in this paper, we leverage the information content of news articles to forecast food price inflation in India. In doing so, we construct a large unstructured dataset consisting of daily news items related to TOP commodities and quantify the sentiment or tone expressed in these articles as a measure of expected price pressures in the TOPcommodities3. We then introduce these news-based sentiment indicators into a time-series forecasting framework to assess whether news-based data can help in improving inflation projections. While there are several studies on inflation forecasting in India, such as Thakur et al., (2016), Maji and Das (2017), Pratap and Sengupta (2019), John et al., (2020) and Jose et al., (2021), none of the studies have explored the predictive ability of news data for forecasting inflation in India. Our study aims to add to this literature through a detailed analysis of news data for predicting food price inflation. Adopting a suite of time-series forecasting models premised on monthly and daily high-frequency data, we show that addition of news-based sentiment indicators to inflation forecasting models can be beneficial. The gains from the information content of news items depends upon the forecast horizon of interest and the frequency of input data. Importantly, our sentiment indicators also prove useful as an input for inflation forecasting when compared to an alternative secondary dataset consisting of daily prices of food items. Accuracy gains from incorporating daily news data in a mixed frequency setup are especially observed in case of near-term projections or ‘nowcast’ of inflation. Primarily, our paper relates to two strands of the literature. The first strand of literature concerns itself with natural language processing (NLP) tasks and text mining. This literature is concerned with the optimal processing of information embedded in various forms of communication – audio, video and written – between humans and machines (Munezero et al., 2014; Liu, 2015; Ravi and Ravi, 2015; and Taboada, 2016). The second stream of literature is housed within the larger time-series forecasting literature. Within this space, coinciding with the advent of big data and internet, there has been an evolving literature aimed at efficiently incorporating alternate data sources (internet searches, news text, etc.) as well as large volumes of data in standard time-series forecasting frameworks, especially those seeking to forecast macroeconomic variables like GDP, investment, consumption, employment and inflation. For instance, Lei et al., (2015), Gandomi and Haider (2015), Larsen and Thorsrud (2019), Shapiro et al., (2020), Goshima et al., (2021), Rambacussing and Kwiatkowski (2021), Tilly et al., (2021) are examples of such work in the context of advanced countries like the US, the UK and Japan as well as developing countries like China. A thorough introduction to the use of text as an input for economic research is provided by Gentzkow et al., (2019), while application of text mining analysis to central banking has been dwelled upon by Bholat et al., (2015). More recently, Aprigliano et al., (2022), Barbaglia et al., (2022) and Ellingsen et al., (2022) also show that news-based text data, especially in the form of sentiment indicators, can improve macroeconomic forecasts over and above hard economic indicators. Priyaranjan and Pratap (2020), Kumari and Giddi (2020), Sahu and Chattopadhyay (2020) and Bannerjee et al., (2021) are examples of related recent work in the Indian context. The rest of the paper is structured into five sections. Section II presents the stylised facts related to the price dynamics of TOP, vegetables sub-group and food group in the CPI. Section III discusses the coverage of our news dataset and construction of sentiment indicators/indices using text-mining techniques. This is followed by a preliminary data analysis to determine the relationship between constructed news-based sentiment indices of TOP and TOP prices in section in section IV. The forecasting performance of sentiment indices is formally analysed in Section V, which is followed by concluding observations and scope for future research as a way forward in Section VI. Forecasting food inflation has been a challenging task in India due to its high volatility and susceptibility to recurrent domestic supply shocks as well as sporadic global food price shocks (Kapur, 2013; Sahoo et al., 2020). The high volatility in food inflation coupled with the high weight of the food group in the CPI basket has resulted in significant contributions of food inflation tooverall inflation during episodes of food price spikes (Chart 1a)4. For instance, contribution of food inflation to headline inflation was almost 67 per cent in November 2013, 62 per cent in July 2016 and 75 per cent in December 2019 (just before the pandemic), while the average contribution during the full period January 2012 to March 2022 was around 47 per cent. Within food, the contributions of vegetables inflation ranged from (-) 374 per cent in January 2012 to 64 per cent in January 2019, although its average contribution during January 2012 – March 2022 was 14.4 per cent against its weight of 13.2 per cent in the CPI-Food (Chart 1b). Vegetables prices, which display high seasonality - with prices easing during winters and hardening during summers - due to the crop production and harvesting patterns in the country impart seasonality to food inflation. Vegetables price inflation is, in turn, driven by prices of TOP, which have a combined weight of 36.5 per cent in the CPI-Vegetables basket (4.8 per cent in the CPI-Food basket and 2.2 per cent in the CPI-Combined basket) (Chart 2). 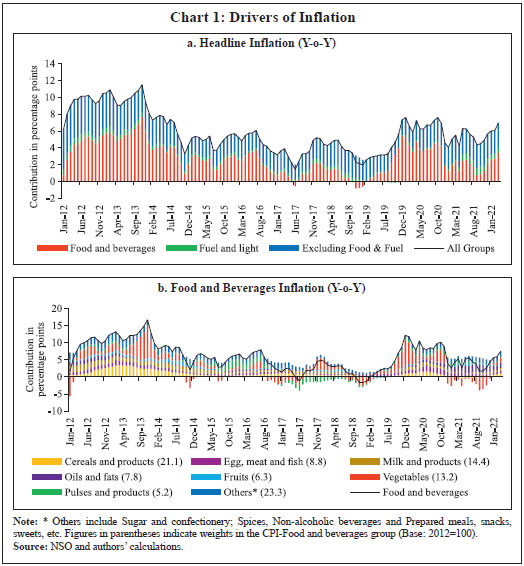 Being seasonal items and subjected to various weather shocks, prices of TOP exhibit large intra-year volatility which, in turn, contributes significantly to the variance of vegetables, food and headline CPI inflation (Chart 3). In fact, the contribution of TOP to the variance of inflation in vegetables rose sharply in 2017-18 and remained elevated thereafter (Chart 3a) explaining a large part of the variance in food inflation in the range of 50-70 per cent and headline inflation in the range of 40-56 per cent (Charts 3b and c). 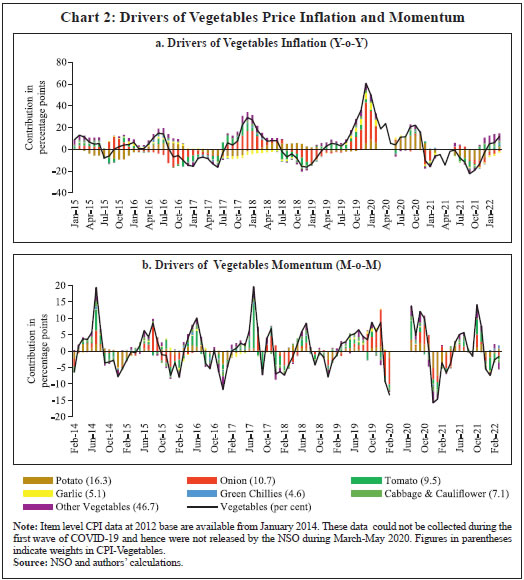 With such high contribution to variance of headline inflation, these three items warrant a closer scrutiny to assess likely build-up of price pressures in the near-term, as a sharp spike in their prices can derail the headline inflation from a stable trajectory. As already stated, India is the second largest producer of these vegetables in the world. However, while consumption of these items is ubiquitous, their production is concentrated in specific parts of the country under different agro-climatic conditions. 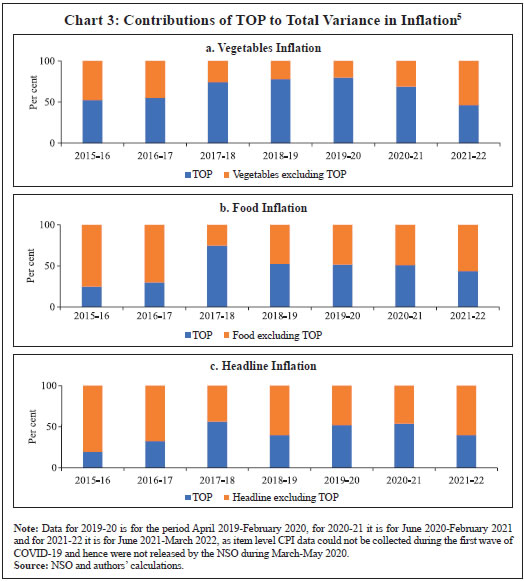 For instance, Maharashtra has the highest share in production of onions, while Madhya Pradesh and Uttar Pradesh are the leading producers of tomatoes and potatoes, respectively (Table 1). The top 5 states had a share of around 76 per cent, 50 per cent and 84 per cent in total production of onions, tomatoes and potatoes, respectively, during the period of 2017-18 to 2021-22. Such a skewed distribution of production indicates probable concentration of risk, emanating from adverse weather events or other supply shocks in these states, which could transmit to all over the country. Market arrivals of the TOP crops in the regional wholesale markets or “mandis” are therefore tracked to form a view about expected price movements in the near-term, such that lower/higher arrivals indicate higher/ lower prices (Chart 4 and Annex Table A8). Such information is available through various government sources like the Agmarknet portal, National Horticulture Board (NHB), National Horticultural Research and Development Foundation (NHRDF) and a few private agencies which track these items. Yet, with fruits and vegetables being delisted from the Agriculture Produce Market Committee (APMC) Act in many states, arrivals data from APMC mandis,may not indicate the true picture with respect to prices6. At the same time, another important source of price information for these items is the Department of Consumer Affairs (DCA) under the Ministry of Consumer Affairs, which collects daily data on prices of essential fooditems from 167 centres across the country7. In case of tomato, onion and potato, these prices have a high correlation of around 99 per cent with corresponding CPI indices (Annex Table A7). Thus, DCA data provide a good indication of price movement of these items for the current month as the data is released on a daily basis and can be used for nowcasting food inflation. But this data cannot be used for understanding the nature of price pressures, for which researchers often rely on news articles, announcements by ministry officials, information from traders and retailers and private agencies that track ground-level information for these commodities. This additional information on factors behind sudden price changes can be utilised to estimate the possible direction and duration of price shock and the magnitude of expected price changes. 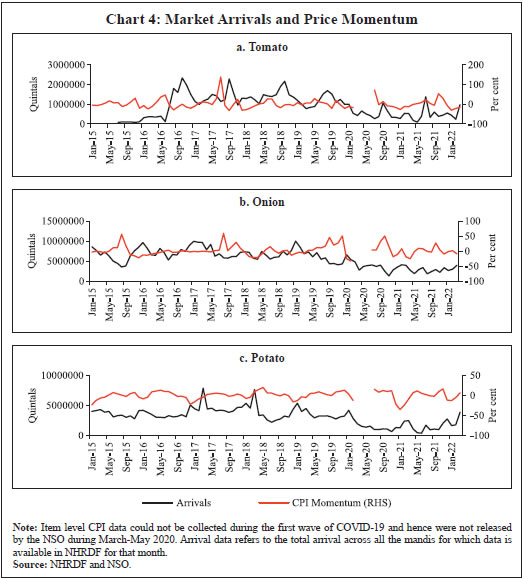 Since TOP items have a high contribution to food inflation volatility and their prices are subject to supply shocks often induced by localised extreme weather events, farmers’ protests, transporters’ strikes, storage losses and sometimes speculative stocking by traders – all of which are covered by local newspapers – news articles related to TOP can provide additional information at an early stage of accumulating price pressures. Such information, which is usually in the form of unstructured data, can be used to create sentiment scores. If these commodity sentiments have lead information about future prices, they can be helpful in nowcasting and forecasting food inflation. Section III For the construction of a news-based sentiment indicator, we develop a novel dataset of daily news items related to TOP commodities from nine leading English news dailies published during January 2011 - August 2021. The newspapers are selected based on their national coverage and reporting on events and issues related to agri-commodities. In the first step, we use generic search terms, such as the name of a given commodity, to extract newsarticles related to a given commodity at scale8. Such text-mining applications are prone to ‘noise’ wherein articles unrelated to the topic of interest might also creep in, thereby lowering the signal-to-noise ratio of the data. Therefore, to avoid noise in the data, we create a set of keywords – ‘supply’, ‘demand’ and ‘prices’ – that capture the market dynamics of TOP commodities. We then filter and retain only those news items which contain at least one keyword each from the set of commodity, supply-demand and price-related keywords.9 This filtering step ensures that the dataset contains only the most contextual and meaningful information for our analysis, to the best extent possible (Chart 5). Finally, the text data are subjected to routine data cleaning procedure, such as removal of stopwords, numbers, white spaces and word stemming, etc., to organise the final dataset containing day-wise news items. 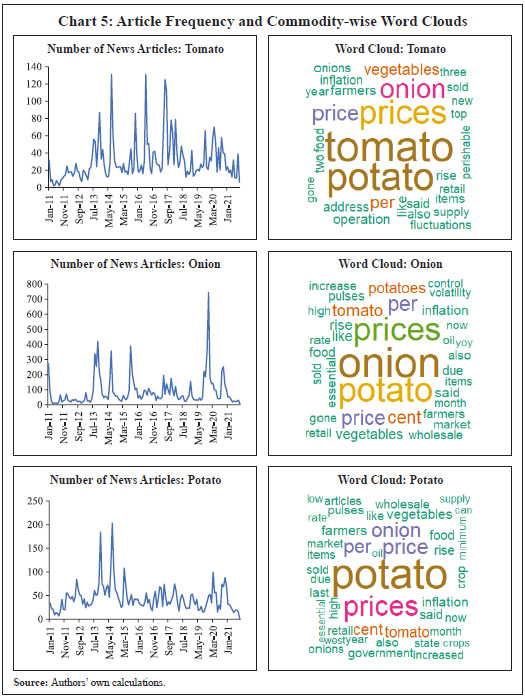 Next, we use the framework laid down by Ardia et al., (2021) for thecomputation of sentiment indices using newspaper text data10. While there are several approaches for sentiment computation, we adopt a lexicon-based approach, in particular a valence-shifting bigrams approach for the computation of commodity-wise sentiment indices. The lexicon-based approach is generally considered flexible, transparent, and computationally convenient as compared to other alternatives (Algaba et al., 2020). Briefly put, this approach matches words (or group of words) occurring in a document with a pre-defined wordlist of polarized (positive and negative) words and assigns quantitative scores to each matching word depending on whether its tonality is ‘positive’ or ‘negative’. For our purpose, the Loughran-McDonald lexicon – designed specifically for analysing economic and financial texts –was used (Loughran and McDonald, 2011)11. More specifically: 1. For each commodity-specific news item, the Loughran-McDonaldlexicon was used to assign a sentiment score {viSi,n,t} to each polarizedword occurring in a news article dn published at time t. The term vi captures the impact of valence shifters or keywords that may negate, amplify or de-amplify polarized words in the given document. 2. Thus, ‘positive’ and ‘negative’ words were assigned a sentiment score of (+1) and (-1), respectively. The scores were then adjusted for valence shifting words depending on whether such words appear before polarized words in the document. It may be noted that this computation occurs at the sentence-level to better account for such valence-shiftingkeywords12.   We assume that a positive (negative) sentiment score is indicative of an expected fall (increase) in the prices of the given commodity. This interpretation is corroborated by the analysis presented in the next section that sheds light on the historical relationship between our constructed sentiments and actual price movements of TOP commodities. Section IV TOP prices exhibit a seasonal pattern which is based on crop sowing and market arrivals across the country. However, they occasionally undergo major spikes due to localised factors, inducing high volatility to overall food inflation. The three vegetables were thus made part of essential commodities and were covered under the Essential Commodities Act, 1955 and hence their prices are monitored regularly by the government. Onion and potato, however, were removed from the list of essential commodities in September 2020 through an amendment to the Act with a rider that these items can be included in the list again only under extraordinary circumstances like wars, famines, or other natural calamities. As expected, the derived monthly net sentiment score of TOP and changes in their prices as reflected in CPI showcase an inverse relationshipbetween them13 (Chart 6). Large increases in TOP prices seen after major supply shocks coincide with large fall in sentiment related to each of the three commodities. Major price spikes observed in TOP in the recent past were often associated with supply shocks. During the period of our study i.e., from January 2011 to August 2021 (more than 10 years), tomato prices have undergone four major price spikes while both onion and potato have undergone five major price spikes. 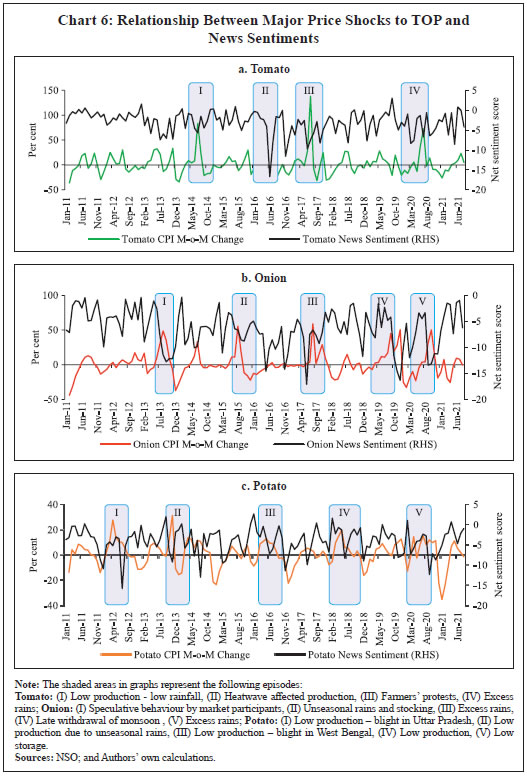 The major causes of these sharp spikes include farmers’ protests, blight disease in potato, speculative stock holding by traders, heatwave, excess rains, etc., but the major and recurring source is related to weather related shocks. Unseasonal, excess or deficit rains affect the production of these perishable vegetables. The extent of price spikes, as measured by the month-on-month (m-o-m) change in CPI indices of these vegetables, i.e., momentum, indicate that the maximum spike was observed in tomato prices in July 2017 (138 per cent), which was the result of farmers’ protests in response to low prices of tomatoes being received by them. The extent of spikes in potato prices, however, is much lower compared to tomatoes and onions (maximum momentum of 31.4 per cent in November 2013). It can also be observed that the sharp spikes in prices usually last for one to two months in case of tomatoes and around three months in case of onions and potatoes. Given the importance of TOP, the government often resorts to supply management measures – like restricting exports, imposing condition of minimum export price (MEP), increasing imports, placing stockholding limits on traders, wholesalers and retailers – to ensure availability in the domestic market and stabilise prices. The inverse relationship between TOP prices as well as their sentiments is also corroborated by the pair-wise statistical correlations for the most recent five-year daily data sample from 2016-2021 (Table 2). For instance, while onion and potato prices have a correlation of 0.45, the correlation between their sentiments is 0.67. Similarly, correlation between prices of tomato with prices of potato and onion is 0.40 and 0.28, respectively, whereas related sentiments exhibit a much stronger correlation of 0.56 and 0.39, respectively. Correlation between the price-sentiment pair of tomato, onion and potato is (-)0.20, (-)0.42 and (-)0.33, respectively. Overall, the correlation between TOP sentiments and prices is negative signifying that a decrease in TOP sentiments is associated with an increase in related prices. As a next step, we subject the daily TOP prices and sentiment indices to a Granger Causality test to ascertain whether news-based sentiments are helpful in capturing the change in prices. Our results show that sentiment Granger causes prices for all the three commodities supporting the argument that the constructed sentiment indices are indeed helpful in capturing the future change in prices (Table 3). The preliminary statistical analysis in the previous sections is indicative of useful forward-looking information contained in the commodity sentiment indices. To formally analyse this, we undertake a time-series forecasting analysis. This section lays down the details of our forecasting analysis conducted using monthly and daily high-frequency data. In the first part of our forecasting analysis, we augment various univariate and multivariate time-series models with our sentiment indices and test their forecasting performance against a benchmark model. Like the news-based sentiment data, DCA provides an alternative set of high-frequency information on prices of food commodities across different centres in India. This data can be regarded as ‘hard’ information which can also be used in inflation projections. Therefore, the second part of our analysis focuses on comparing the forecasting performance of models augmented with sentiment data vis-à-vis DCA price data for TOP commodities. In the final part of our analysis, we showcase how daily high-frequency sentiment indices can be used to forecast CPI-Food inflation in a mixed-frequency sample framework. V.1. Forecasting using Monthly Data For the formal forecasting analysis, we consider monthly changes in CPI-Vegetables and CPI-Food & beverages, both in month-on-month (m-o-m) and year-on-year (y-o-y) per cent change terms, as our target variables. Thus, we have four different target variables. In line with standard practice, we divide the full sample of data into a training and a testing sample. The train sample, from January 2011 to August 2019, was used for estimation of the models. The test sample, from September 2019 to August 2021, was used for comparing model forecast performance in terms of the root mean-squared error (RMSE) of forecasts generated by different models. We consider different specifications of autoregressive integrated movingaverage (ARIMA) models14. Taking the approach of parsimony, we combine all TOP-related news articles and use the sentiment scoring method described in section III to construct a composite TOP sentiment index. We introduce this index into our suite of ARIMA models to assess whether inclusion of such news-based information leads to gains in forecasting accuracy. Following Jose et al., (2021), other drivers of domestic food prices, such as global food prices, rainfall and minimum support prices (MSP), were also included as control variables in the forecasting model for robustness (additional results provided in the Appendix). The out-of-sample forecast performance of various models is provided in Tables 4-7. To capture the performance of models augmented with sentiment data over time, we combine the standard out-of-sample forecasting approach with a rolling window to ensure a dynamic and robust evaluation of model forecast performance across horizons. For ease of comparison, we present the results in terms of relative performance vis-à-vis a benchmark AR(1) model, where relative performance is defined as RMSE of model m at horizon h scaled by the RMSE of the benchmark model for the same horizon. Any value less than one suggests gains in forecasting accuracy as it indicates that the actual RMSE value for a given model is lower than that of the benchmark model. Beginning with Table 4, which presents results for the m-o-m changes in CPI-Vegetables series, almost all models from M2-M6, are able to outperform the benchmark AR model (M1) across different horizons, particularly less than 6-months. However, addition of sentiment data is seen to improve forecasting performance across all horizons. For instance, augmenting a simple AR(1) model with NSS (M2) results in forecasting gains of about 2-6 per cent across horizons. Similarly, adding NSS to seasonal ARIMA model (M6 vs. M5) leads to better forecast performance, such that M6 is able to generate accuracy gains to the tune of 7-10 per cent over the benchmark across horizons. Forecasting performance in case of y-o-y measure of CPI-Vegetables showcases the benefits of incorporating news-based information even further, especially at the near-term horizon (Table 5). While not much improvement is seen in case of ARIMA models (M2-M4), SARIMA models deliver better forecast performance. The forecasting performance of models for the m-o-m changes in CPI-Food and beverages, however, are mixed (Table 6). The AR(1) model augmented with NSS delivers better forecast performance compared to the benchmark model, although these gains are comparatively modest (2-5 per cent) relative to CPI-Vegetables. Rest of the models fails to outperform the benchmark. Lastly, in case of CPI-Food and beverages y-o-y series, SARIMA model (M5) and SARIMA model with sentiment information (M6) provides the best forecasts (Table 7). As seen in the earlier cases, adding sentiment information to forecasting models leads to a general improvement in forecasting accuracy. V.2. Forecast Comparison between Sentiment data and DCA Data To compare the extent of forward-looking information embedded in news-based ‘soft’ data and ‘hard’ DCA data, we estimate separate bivariate vector autoregression (VAR) models containing each set of indicators and compare their out-of-sample forecasting performance. A bivariate VAR model can be generally expressed as follows: 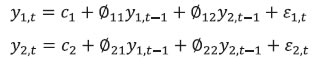 where yi,t represents a set of endogenous variables whereas Ɛ1,t and Ɛ2,t are white noise processes that may be contemporaneously correlated. Our basic framework, including the target indicators, forecast horizon and train-test sample, remains the same as in the last subsection15. We estimate the VAR model using ordinary least squares (OLS) method while choosing optimal lag structure via the AIC criterion. The forecasting performance based on rolling out-of-sample forecasts, in the form of relative RMSE with respect to a benchmark AR(1) model, is provided in Table 8. In case of CPI-Vegetables inflation, both set of indicators showcase a similar forecasting ability across time horizons. In some cases, such as m-o-m CPI-Vegetables model augmented with sentiment or DCA data fail to outperform the benchmark. However, in case of CPI-Food & beverages inflation, bivariate VAR model with sentiment data outperforms both the benchmark and DCA data-based model across horizons. In case of m-o-m measure, the gains in forecasting accuracy range from 13 to 32 per cent, whereas even higher gains ranging from 56 to 75 per cent accrue when sentiment data is used to forecast the CPI-Food & beverages y-o-y measure of inflation. This highlights the efficacy of sentiment data for forecasting inflation over and above the only other existing high-frequency prices data provided by DCA. V.3. Forecasting using Mixed-frequency Data: A MIDAS Approach Having access to high-frequency news data, we exploit the information embedded in daily news sentiments to forecast monthly inflation series. A mixed data sampling (MIDAS) regression approach comes in handy by allowing the use of data sampled at different frequencies in the same regression. In particular, the MIDAS methodology proposed by Ghysels et al. (2002; 2006; 2007) and Andreou et al. (2010) allows the estimation of regression models where the dependent variable is sampled at a lower frequency compared to one or more of the independent variables. Thus, MIDAS helps in incorporating the information in higher-frequency data into the lower frequency regression model in a flexible and parsimonious way. A MIDAS regression model can be generally specified as follows: 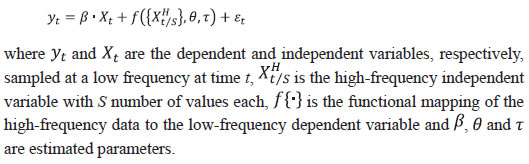 Traditional approaches to mixed-frequency regression either introduce a sum/average of the high-frequency data with a single coefficient (implicitly equal weights) or include individual components of the high-frequency variable in the model allowing for separate coefficients. On the other hand, by allowing for several different weighting functions to decide optimal weights and reducing the number of estimated parameters by placing adequate constraints, the MIDAS approach offers a flexible framework to incorporate high-frequency information into a regression model. Various weighting schemes available under this approach are (a) step-weighting; (b) polynomial distributed lag (PDL) weighting; (c) exponential PDL weighting; (d) normalised beta function weighting; and (e) individual coefficients weighting technique (U-MIDAS). Adopting a similar train-test approach as in the previous sub-section, we use a simple AR(1) model estimated using the MIDAS framework with PDL and U-MIDAS weighting techniques for predicting our target variable. We incorporate the high-frequency information by introducing up to 30 lags of combined TOP net sentiment score computed at a daily frequency. The out-of-sample forecasts on test data are generated using the dynamic rolling window approach from one-to 12-months ahead horizon. The forecast performance, in the form of relative RMSE of forecasts generated by best-performing MIDAS model compared to the AR(1) benchmark, is presented in Table 9. As is evident from Table 9, leveraging daily news-based sentiment data has clear benefits in terms of gains in forecasting accuracy in m-o-m space. In case of m-o-m changes in CPI-Vegetables and CPI-Food and beverages, the MIDAS model with daily data outperforms the benchmark model at the one-month ahead horizon. In addition to these one-month ahead predictions or nowcasts, the MIDAS model outperforms the benchmark for two- to six-months ahead horizon, where the gains range from 2-5 per cent for m-o-m changes in CPI-Vegetables and CPI-Food and beverages series. On the other hand, sentiment augmented model fails to outperform the benchmark model in case of inflation measures taken in y-o-y terms across different horizons. Thus, overall, it can be said that daily news-based sentiment indicators for TOP commodities can help near-term month-on-month projections of price index for CPI Vegetables and CPI Food and beverages over different forecast horizons. Section VI Recurrent supply disruptions driven by unseasonal rainfall, floods, droughts, pest attacks, protests by farmers/transport operators, etc., makes the task of inflation forecasting an arduous challenge in India. In this study, therefore, we develop a novel dataset consisting of news articles related to three main agricultural commodities viz., tomato, onion and potato or TOP to forecast CPI-based inflation in vegetables and food & beverages. We quantify the information content of news articles using natural language processing (NLP) techniques to assess whether news-based alternate data can help in achieving better forecasts. Through various forecasting methods premised on monthly and daily data, we provide empirical evidence to conclude that news-based data in the form of sentiment indices provides gains in forecasting accuracy. The forward-looking information content embedded in news data, therefore, suggests the use of news-based sentiment indicators as an additional source of information for inflation forecasting. This is crucial from a policy perspective in an environment of highly uncertain food price dynamics that are increasingly becoming climate dependent. While this study is a first step in the direction of using news-based big data for food inflation forecasting, the analysis can be extended in several ways. From the perspective of forecasting headline inflation and its components, a larger number of commodities and other items corresponding with the official CPI basket can be included in the forecasting framework. More nuanced NLP techniques, such as those based on supervised machine-learning methods for sentiment quantification, or unsupervised topic modelling approach can be used to derive more granular information on topics such as supply and demand for various items. The suite of time-series methods can also be expanded to experiment with other advanced techniques, such as dynamic factor models, penalized regressions and deep learning models which might help achieve better forecasting accuracy. Moreover, given the forward-looking content of news-based data, it can also be used for turning point analysis of inflationary shocks to the economy. Finally, while we have focused on point forecasts in this paper, it remains to be seen whether news-based information can also help in reducing the uncertainty around forecasts. We leave these issues for future research. References Aprigliano, V., Emiliozzi, S., Guaitoli, G., Luciani, A., Marcucci, J., & Monteforte, L. (2022). The power of text-based indicators in forecasting Italian economic activity. International Journal of Forecasting. Algaba, A., Ardia, D., Bluteau, K., Borms, S., & Boudt, K. (2020). Econometrics meets sentiment: An overview of methodology and applications. Journal of Economic Surveys, 34(3), 512-547. Andreou, E., Ghysels, E., & Kourtellos, A. (2013). Should macroeconomic forecasters use daily financial data and how? Journal of Business & Economic Statistics, 31(2), 240-251. Ardia, D., Bluteau, K., Borms, S., & Boudt, K. (2021). The R package sentometrics to compute, aggregate and predict with textual sentiment. Journal of Statistical Software, 99(2), 1-40. Banerjee, A., Kanodia, A., & Ray, P. (2021). Deciphering Indian inflationary expectations through text mining: an exploratory approach. Indian Economic Review, 1-18. Barbaglia, L., Consoli, S., & Manzan, S. (2022). Forecasting with economic news. Journal of Business & Economic Statistics, 1-12. Bholat, D., Hansen, S., Santos, P., & Schonhardt-Bailey, C. (2015). Text mining for central banks. Available at SSRN 2624811. Ellingsen, J., Larsen, V. H., & Thorsrud, L. A. (2022). News media versus FRED-MD for macroeconomic forecasting. Journal of Applied Econometrics, 37(1), 63-81. Gandomi, A., & Haider, M. (2015). Beyond the hype: Big data concepts, methods, and analytics. International Journal of Information Management, 35(2), 137-144. Gentzkow, M., Kelly, B., & Taddy, M. (2019). Text as data. Journal of Economic Literature, 57(3), 535-74. Ghosh, S. , Kundu, S., & Dilip, A. (2021). Green Swans and their Economic Impact on Indian Coastal States. Reserve Bank of India Occasional Papers, 42(1). Ghysels, E., Santa-Clara, P., & Valkanov, R. (2002). The MIDAS touch: Mixed data sampling regression models. Working Paper, UNC and UCLA. Ghysels, E., Santa-Clara, P., & Valkanov, R. (2006). Predicting volatility: getting the most out of return data sampled at different frequencies. Journal of Econometrics, 131(1-2), 59-95. Ghysels, E., Sinko, A., & Valkanov, R. (2007). MIDAS regressions: Further results and new directions. Econometric Reviews, 26(1), 53-90. Goshima, K., Ishijima, H., Shintani, M., & Yamamoto, H. (2021). Forecasting Japanese inflation with a news-based leading indicator of economic activities. Studies in Nonlinear Dynamics & Econometrics, 25(4), 111-133. John, J., Singh, S., & Kapur, M. (2020). Inflation forecast combinations – The Indian experience. RBI Working Paper Series, No. 11/2020, Reserve Bank of India, Mumbai, India. Jose, J., Shekhar, H., Kundu, S., Kishore, V., & Bhoi, B. B. (2021). Alternative Inflation Forecasting Models for India–What Performs Better in Practice?. Reserve Bank of India Occasional Papers, 42(1). Kalamara, E., Turrell, A., Redl, C., Kapetanios, G., & Kapadia, S. (2020). Making Text Count: Economic Forecasting Using Newspaper Text. Bank of England Working Paper No. 865, Available at SSRN: https://ssrn.com/abstract=3610770 or http://dx.doi.org/10.2139/ssrn.3610770 Kapur, M. (2013). Revisiting the Phillips curve for India and inflation forecasting. Journal of Asian Economics. 25(1), 17-27 Kishore, V. and Shekhar, H. (2022), Extreme weather events and vegetables inflation in India. Economic and Political Weekly. Forthcoming. Kumari, S., & Giddi, G. (2020). Inflation decoded through the power of words. RBI Monthly Bulletin, May, Reserve Bank of India, Mumbai, India. Larsen, V. H., & Thorsrud, L. A. (2019). The value of news for economic developments. Journal of Econometrics, 210(1), 203-218. Lei, C., Lu, Z., & Zhang, C. (2015). News on inflation and the epidemiology of inflation expectations in China. Economic Systems, 39(4), 644-653. Liu, B. (2020). Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge University Press. Loughran, T., & McDonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. The Journal of Finance, 66(1), 35-65. Maji, B., & Das, A. (2016). Forecasting inflation with mixed frequency data in India. Calcutta Statistical Association Bulletin, 68(1-2), 92-110. Munezero, M., Montero, C. S., Sutinen, E., & Pajunen, J. (2014). Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Transactions on Affective Computing, 5(2), 101-111. Priyaranjan, N., & Pratap, B. (2020). Macroeconomic Effects of Uncertainty: A Big Data Analysis for India. RBI Working Paper Series (No. 04/2020), Reserve Bank of India, Mumbai, India. Pratap, B., & Sengupta, S. (2019). Macroeconomic forecasting in India: Does machine learning hold the key to better forecasts?. RBI Working Paper Series, No. 04/2019, Reserve Bank of India, Mumbai, India. Rambaccussing, D., & Kwiatkowski, A. (2020). Forecasting with news sentiment: Evidence with UK newspapers. International Journal of Forecasting, 36(4), 1501-1516. Ravi, K., & Ravi, V. (2015). A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowledge-based Systems, 89, 14-46. Reserve Bank of India. (2021). Monetary Policy Report, October. Sahoo, S., Kumar S. and Gupta B. (2020). Pass-through of international food prices to emerging market economies: A revisit. Reserve Bank of India Occasional Papers, Vol. 41, No. 1: 2020 Sahu, S., & Chattopadhyay, S. (2020). Epidemiology of inflation expectations and internet search: an analysis for India. Journal of Economic Interaction and Coordination, 15(3), 649-671. Shapiro, A. H., Sudhof, M., & Wilson, D. J. (2020). Measuring news sentiment. Journal of Econometrics, 228 (2), 221-243. Taboada, M. (2016). Sentiment analysis: An overview from linguistics. Annual Review of Linguistics, 2, 325-347. Thakur, G. S. M., Bhattacharyya, R., & Mondal, S. S. (2016). Artificial neural network-based model for forecasting of inflation in India. Fuzzy Information and Engineering, 8(1), 87-100. Tilly, S., Ebner, M., & Livan, G. (2021). Macroeconomic forecasting through news, emotions and narrative. Expert Systems with Applications, 175, 114760.
* Bhanu Pratap (bhanupratap@rbi.org.in), Abhishek Ranjan (abhishekranjan@rbi.org.in), Vimal Kishore (vimalkishore@rbi.org.in) and Binod B. Bhoi (binodbbhoi@rbi.org.in) are from the Department of Economic and Policy Research (DEPR), Reserve Bank of India, Mumbai. The authors are thankful to Harendra Kumar Behera, Shweta Kumari and an anonymous referee for their helpful comments and suggestions on the paper. The views expressed in the paper are those of the authors and do not represent the views of the Reserve Bank of India. 1 Headline inflation is measured by year-on-year changes in the all-India CPI-Combined (Rural + Urban) with base year: 2012=100 released by the National Statistical Office (NSO), Ministry of Statistics and Programme Implementation, Government of India. 2 PIB link - https://static.pib.gov.in/WriteReadData/specificdocs/documents/2021/oct/doc2021102961.pdf 3 According to Munezero et al. (2014), sentiment is one of the so-called human subjectivity terms that may reflect a person’s desires, beliefs, and feelings that are features of a person’s private state of mind which can only be observed through textual, audio, or visual communication. Algaba et al. (2020) define sentiment as “the disposition of an entity toward an entity, expressed via a certain medium”. 4 The share of food and beverages in overall consumer price index - combined basket is 45.86 per cent (Base: 2012=100). 5 Contribution of subgroup (say, A) to variance in total (A+B) is calculated using the following formula: Contribution (A) = W(A)W(A) Cov(A, A) + W(A)W(B) Cov(A, B), where W is the weight of the sub-group and Cov is covariance. 6 For instance, Assam and Meghalaya delisted fruits and vegetables in January 2014, Delhi in September 2014, Odisha in February 2015, Gujarat in April 2015, Maharashtra in July 2016, etc. 7 Coverage of centres keep changing, earlier it was around 120. 8 The news dataset has been constructed using application developed by Meltwater Inc., https://www.meltwater.com/en. 9 The keyword sets are as follows: commodity = (onion/tomato/potato, onions/tomatoes/ potatoes); prices = (price, prices, inflation); supply-demand keywords = (increase, increases, increased, hike, hikes, rise, rose, rising, surge, surges, surged, soar, soaring, climbed, climbing, skyrocketed, skyrocketing, shoot, push, peak, peaked, fall, fell, decrease, decreases, decreased, crash, crashed, plunge, plunged, drop, dropped, decline, declined, down, cool, cooling, tumbled, slipped, harvest, rain, rainfall, flood, floods, flooding, rain damage, destroy, destroyed, stock, stocking, market arrival, market arrivals, arrivals, arrival, production, supply, bottleneck, supply chain, shortage, shortages, export, sowing, sowing delay, spoiled crop, rotten, hoarding, cold storage, transport strike, truckers strike, pest attack, drought, demand, increased demand, high demand, festival demand, bumper crop, supply, supply glut, higher production, supply boost, import, export ban, fresh crop arrivals, increased market arrivals, stock limit, stock limits, hoarding, buffer stock, low demand, sluggish demand, weak demand, lack of demand, hailstorm, unseasonal, protest, farmer protest, protests). 10 We use the R sentometrics package for end-to-end computational purpose. 11 The dictionary can be accessed here - https://sraf.nd.edu/loughranmcdonald-master-dictionary/. 12 Valence-shifting keywords tend to negate, amplify or de-amplify the meaning of other words thereby changing the tone of the sentence. For instance, “this is not good” would be assigned a score of (+1) under the normal sentiment scoring approach. However, it would be assigned a score of (-1) due to the presence of a negating word ‘not’ under the approach adopted by in our case. 13 As mentioned earlier, CPI item level data were not released by NSO during March-May 2020. To create a continuous series of CPI indices for tomato, onion and potato – for comparison with sentiment indices and for charts – momentums of DCA for tomato, onion and potato were used to impute corresponding CPI indices for the missing months, given the high correlation between the two. 14 ARIMA and SARIMA are popular time-series models due to faster computation, interpretation and better predictive ability for short-term forecasting. ARIMA and seasonal ARIMA methods are frequently used for inflation forecasting in the Indian context (Jose et al., 2021). Model selection in case ARIMA(p,d,q) and SARIMA(p,d,q)(P,D,Q) was done using the Akaike Information Criterion (AIC). Model estimation was done using maximum likelihood estimation (MLE) technique. 15 To ensure the stationarity condition, CPI-Vegetables, CPI-Food & beverages and DCA price data are taken in y-o-y (per cent) or m-o-m (per cent), as applicable for a given model and target indicator. The composite TOP sentiment index is taken in level form since it was found to follow an I(0) process. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Share this page:






Install the RBI mobile application and get quick access to the latest news!
Scan the QR code to install our app



Page Last Updated on: September 12, 2023










