 IST,
IST,





Unedited Transcript of the First Suresh D. Tendulkar Memorial Oration delivered by Prof. Abhijit Banerjee, MIT, Boston, USA on January 19, 2013
Prof. Abhijit Banerjee, Guest Speaker
Delivered on Jan 19, 2013
|
Thank you very much Governor Subbarao for this generous introduction and thank you very much for inviting me to give this oration. I am a great fan of Professor Suresh Tendulkar. He was a one of a kind, very straight forward, very direct. When I said something he would disagree with, he would listen and come out and say that it does not make any sense and I had to defend myself there. It was always an honour defending myself against him. He had perceptive things to say and he was always unfailingly interested in what the discussion was on which I think is often not the case. We worked in different areas. His one big area was measurement of poverty, my work on the most part has been more on how to do something about poverty, what are effective and ineffective interventions. So the places where I thought our parts crossed little more are how to find the poor per say, how to set the poverty line. Suppose you set the poverty line and you don’t know who is out there. Potentially, several hundred million poor people live in several hundred thousand villages. I mean how to find them is the question. I am going to spend all the time talking about how do we go about the view that we need to do something about the poor. For example, we need to provide them with bank accounts then how do you go from there to actually giving the bank accounts if you don’t know where they live or who are they. That’s the question we will look at. I think it is a hard question for several reasons. If you want to go and find the poor it’s not enough to just survey them. A sample survey like NSS is an excellent survey which gives you in which state or which district more poor people live. But it does not tell you who those poor people are. So you really need a census if you really want to implement a NSS method of identifying the poor You want to go to every single person or maybe you leave out the rich areas of the city and just go to the places where the poor live. You need to go a lot of places, interview household by household, collect data about all those households. That’s an amazingly elaborate task, especially if they want to do it frequently because after all poor people become rich and rich people become poor. So you have to do it often. So no country does that. What they so is proxy means testing or PMT. It is a kind of a survey, a census based methodology. It does not require actually a survey. It is basically to identify that if you own a car you are not poor, so we can check that. If you have a big brick house, you are not poor. So basically you identify a set of durables easy to observe and if you own any of them or any 5 of them, then you are not poor. That is the rule that lots of countries use and it is called a proxy means testing. A standard way of identifying the poor is by using any version of this. Anybody who has a motor cycle is not poor, anybody who has gas cooker is not poor. The second way of identifying is what we in India have used - community based targeting. The idea would be that you go to a local community and ask them who the poor in this area are. They give you a list of people and there would be some political process you might go through there, might be some review and the panchayat might say that this might include these people. The 3rd method is what we have implemented in NREGA. It is essentially direct targeting ; let people just go and be there. If you want a job digging ditches in the middle of the summer, you can always have it. That is the philosophy of MNREGA. We don’t need to know who is poor, we will just offer them a job. If they take the job of digging ditches in the middle of the summer, then they are poor because no one else would want that job. Worldwide these are 3 different models. What lot of countries do is, first, they have community based targeting, then somebody goes and does the PMT on them and checks whether though the community says Mr. X is poor they go and find that he actually has 3 cars, then he is less poor. So there is some way of doing it by combining the methods. So I want to spend the entire lecture talking about which of these works best. It is not an easy question. There are programmes in India like the PDS which is targeted, through more of community-based targeting, and the MNREGA which is self-targeting. The quality of targeting in PDS and the quality of targeting in MNREGA is different for many other reasons. They are implemented differently, they have different history, the people who run them are different. So you can’t tell whether they work better. If the same identification method was implemented by the same people which one would work better cannot be answered by comparing the different programmes as they are run differently. That’s the challenge. Then I will also spend a little bit of time talking about the second question. Imagine that I decide that community-based targeting is the best in that there are still many different ways of doing it when you do community-based targeting. You get the entire community into a meeting, it is a very difficult thing to do because people are busy. You have to work pretty hard to get them in to a room, then you ask them to identify the poor or you could just take the village leadership and you could ask them. You might think it is worse because leadership might promote their friends and but on the other hand they are cheaper because there are 10 people rather than 400 people. So you have a trade-off - getting 400 people or organizing 10 people which is easier to organize or MNREGA which is a case of self-targeting. Every day you go and self target yourself. But you could do something different. You could say come every month and put your finger print but you get paid for the whole month. You don’t need to come to work every day. That is also going to generate self selection. You will make selection more straightforward, by having people coming and signing up once a month rather than once a day. If you transfer money to people then it might be easier to do. So it is a trade-off between these models. What I want to talk about is among these models which one you know is the best. I am going to talk about experiments, large-scale field experiments. The villages are largely randomly chosen so that when they are chosen, there is no systematic difference between them. Some of them get self-targeted and then you see what happens, where you get better targeting. I will give you an example of India. This is the only example I have of our work in India but an interesting one. This is a programme for targeting the hardcore poor. It is a programme run by an MFI called BANDHAN in West Bengal. This is a programme which uses a community route. The whole community is brought together by drawing maps and physically identifying where poor live. They check this with the census. So this programme was generating what kind of selection? This was asking who was the poorest of the poor and not the poor. So this is a different question and these people were poorer than the average poor person in the village. That is important to remember. In this case we thought there is little evidence that there will be inclusion error in the sense that the people who are not poor would be called poor. Those people were going to get about Rs. 8,000/- worth of free goods – they were being given free cow or money. So the giveaway was significant and the village community as a whole did not include rich people. What happened was there were lots of inclusion errors. Basically the people who got excluded were the people who lived on the boundary of the village. So people who are from tribal communities and other people who lived on the margins of the village were excluded. The village community got whom they recognized to be their own member. They were relatively good in identifying people but not when it came to people whom they did not count in the community. Some of the poorest people were left out. This may just set up the vocabulary. What I now want to talk about is 2 large experiments that we carried out in Indonesia. The reason why we did it there was that the Indonesian government asked us to do it. The government there is very technocratic. If you are being working with them for a while they will ask you that we want to move away from this PMT, which is that you go on collecting this asset data method on to a different method, so how well will that work. So the question asked was how does the PMT compare with the community data method. The Government of Indonesia occasionally decides that every poor person will get certain amount of money. This was one of those one time programmes. It was not a huge transfer. The idea was that this would be given to people who had per capita consumption below, at purchasing power parity, 2 dollars per day. This was randomized across 640 hamlets. Indonesian villages are like Indian villages especially the ones in Rajasthan. So the PMT methods that the government there uses have 49 indicators. You go to a household, you make a list of how many things it has, is it a brick wall or a mud wall, is it a thatch trash roof or a tin roof, do they have a TV, a motorbike, etc. They calculate that and based on that they then decide that, say, if a household has motorbike and tin roof then they are not poor. So there are some rules and they use that. They go to every household, collect this data and then they use these rules. The government sends numerators to collect this asset data. Basically it is the predicted score that comes from this data, they say if you have this characteristic, you have this and if your score is low enough you get your money. So that is one way to do it. This was done in about one-third of the villages. The alternative was to use the community method. There were two ways of doing the community method - one was based on all households being invited and they were encouraged to come. Every household is indicated as a card. If you ask them I want to rank this household, so I put a string across the room and I hang cards. This is the way they do it - if I am poorer than some other household, then I am put to the left of that household, if I am richer I am put to the right. Every household is then ranked in this way. The other way is by inviting only the elites. There were three groups - 640 people were divided into 3 groups. One group go the PMT way, the other went the community way. Then there is what I would call a hybrid – they were first identified by the community people and then the government went and verified who they had picked and checked whether they had picked the right people. So the government had an exclusion role, they could remove people they thought were not poor. So this is a mixture of the two. This was done in 2008-09. 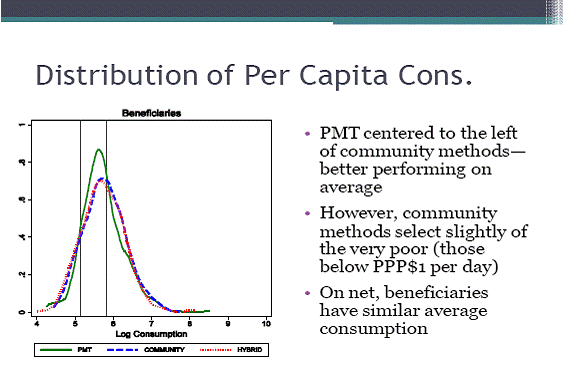 Now here is the basic result. The distribution of consumption in the 2 methods the hybrid and the community method look the same. The red dotted curve and the blue curve look exactly the same. The PMT is significantly different and on an average is the better one. The government method is better then the community method. If you ask the community to get slightly less poor people on average, if you see, the green curve is peaked to the left of blue and red curve meaning that the government method is picking poor people better. Not big difference, though. Basically if you look at the measure of mistargeting that is how many people who are not poor got added and how many poor got included in non poor, then you find there is a 3% difference. So the proportion of mistargeted people went down by 3% when you move to the government method. So you can say community did slightly worse on identifying the poor. Actually, in terms of identifying the very poorest, people who are really below the poverty line, the community method does better. On the whole, however, it does not do better. This was what the government there was really interested in. We also asked them are you happy with the outcome. After the targeting was done, the money was distributed. Six months after all this was done, we went and asked them that which did you think was a good process. The community by far preferred its own method. We then went to every household and privately asked them which method did they like and which they didn’t. We asked them on a scale of 1 to 10 where will you put the outcome and people were willing to put the community outcome at an higher level than the government outcome. People thought community outcome was fair even though as you can see it is worse in picking the poor people. So why did the government do better or differently? The first possibility is that the community is captured by the elite. The elite just take a decision and then they implement it. I said I will the look at two different versions - one is by asking the whole community to come and the other is by inviting just the top 10 village officials to come. It actually makes no difference whom you invite. Either you invite only the village officials or rest of the people, they pick the same people. It is not because of elite capturing it, somehow the elite just add their friends to it and so you get a different outcome. The other thing we did is to randomize the order in which people were ranked. There are 400 people and you have to rank them one by one. So how did you do? We chose randomly who gets first rank and at the end it turns out that the people in the community does very well for the first half an hour and then they get tired and the errors keep going up. Towards the end, they were just saying put him anywhere. The community just got extremely tired of this thing. So we were just making demands of them for ranking this people we thought they must know. Who is poor would be easy for them to tell but they found it difficult as we randomized the order. We could see exactly what was happening there. One way to look at that is to look at the correlation between how the village rank this people and they rank themselves. If they ask are you very poor, people say yes some say no. But it turns out that the community is much more sensitive to people’s self description than the government. The latter method actually pretty much ignores this information. We correlated that with what people say. The community’s goals seem to be somewhat different than what the government method was doing. Interestingly the community seems to be identifying qualities of household that are not picked up by the government methods. It basically picks up per capita consumption but other things matter too. It matters whether you are lazy or not. The community is against lazy people. Those people who have a high level of education but at the same time live off others, the community thinks those people should not be treated as poor. The community thus has its own views on who deserves to be called poor. If one has a high school education and the other has no education and they are earning the same amount, then the community’s view is the guy who has had high school education is lazy, that’s why he is not making the money that he should. So he is not poor. In a way they are not targeting consumption, they are taking a moral judgement on who is poor. On the other hand, anyone, even if you have the same consumption level, like a widow must be working very hard to have this consumption level. Then they reward those people, like if you are disabled, even with the same consumption level of somebody who is fully able, you are likely to be counted as poor. So they are looking beyond consumption. This is a very interesting fact as the reason why the community does badly or does not meet up with the government’s aims, is not only, as I said, they get tired but the important part is they also have a different view of who is poor. There is moral judgement in that. We may agree or disagree with the moral judgement. The community is not trying to do what the government is asking them to do. So that is an important result to keep in mind. If you look at somebody’s consumption rank, if the community says this guy is poor does it contain information above or beyond the information contained in the PMT. We know the answer is yes, so the community is able to say that this person, even though he owns a motorbike, he is really not rich. He is actually poor. On that assumption, the community is doing better. They seem to have better information. They are using the information the way we want them to use it. The first set of conclusion is that the community is happy when they do the picking. I think their view is we know who the poor are you don’t. So if you let them do it they are much happier. You could say it is not easy for them to do the ranking. They tend to be petty, they start making mistakes. So both models have problem. Even if you let the elites decide, they take the same decision as the rest of the community. That suggests the community does not do a bad job and they are happy doing it. Now the next question is how well the government selection, the PMT method, compares with self selection as in MNREGA. The idea of self selection implies a mechanism that somebody who is richer, standing in the line and digging ditches is not worth their time. They must be doing something more productive and prefer more leisure. For those few rupees, they are not going to stand in line in the sun or dig a ditch, they can earn doing something else. If they don’t want to earn they can watch TV. There is no reason to do it. In self selection that is the basic theory. That’s the reason why we think this scheme should work. This is not always the case. If I tell you today you have to go and stand in line to get money in the future, well if you are very poor, you will not have that time as you don’t have food today. So you may worry that you may miss the poor. The second worry is that the poorest are often people who tend to have other problems. It may include a single woman with multiple children or a woman with multiple children who has a husband who is alcoholic. What do they do with the children? Now some of the MNREGA programmes have crèche facility but most of them don’t. So self targeting would impose higher cost on the poor. As for the non poor, they have good social network and connection. There may be some relative who can take care of their children. The poor often are isolated socially, so they cannot find someone to help them. So self selection might hurt the poor. There are also worries that it is not sure you are going to get the right kind of self selection. So after we delivered the results of the previous programme, we did this experiment in 400 villages in 3 prominences in Indonesia again. This generous programme gives people 11% of their annual consumption as a free gift for 6 years, basically up to 150 dollars a year for 6 years. It is a substantial amount for the poor. The question was how do we do it if we just have self selection. Villages are randomly chosen for self selection. This is however very different from MNREGA that is in this case you have to go every day to collect the money. In the beginning, the Indonesian government was not agreeing to create work sites. What we did was to set up an office where people can come and sign up. So people have to pay the cost as one might have to stand in the line for 3 to 4 hours. Once you sign in, someone will come to your home and check whether you are actually eligible or not. If you don’t think you are going to get it, then don’t bother signing up. There is no point signing up because we will come and check. As you have to stand in line for 3 to 4 hours, you need very strong incentive to show up. Someone interviews you and enters the data in the computer and at some places you have to go 2 to 3 kms away from your home. So there is some cost, it may not be huge but it is also not zero. So the first question is who self selects. The other way of doing this is the information that I have about myself no one else knows it. May be I own a motor bike and I have a decent house, but I just lost my job. That’s not going to be anywhere in that government checklist. So one advantage of self targeting is to be flexible if I need I will come if I don’t need I will not come. The government does not have to figure out every day that I lost my job or not. So there is flexibility. 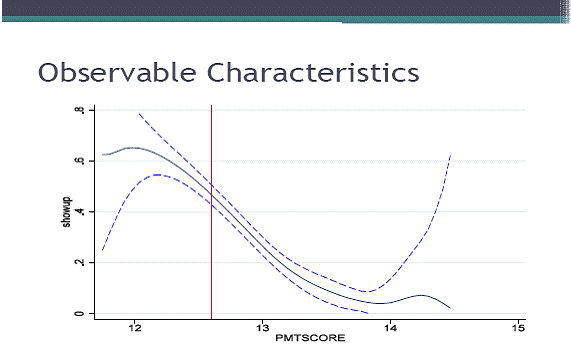 The green line shows you the probability of your PMT score, your asset score that the government uses to include you or not. So if I measure you PMT score and it goes from 12 to 14, the answer is the probability goes down a lot. While 60% of people show up, roughly 0% show up by the time you get to the PMT score of 14. Here you are selecting the people with worst assets. Even though this is a very lucrative programme, only 60 % show up. That is something to keep in mind. If you run the regression of the actual consumption, your PMT score there will be error score which says that this person is poor and this person is richer. So imagine I take the list of the assets and predict consumption, there will be a prediction error which says the model is not perfect. A person who owns a motor bike is poorer than other people who don’t own a motor bike. Is this error predicting whether you would show up or not? The answer is yes. If you are richer than you look, based on your asset, then you don’t show up. If you are poorer than you look, based on your asset, then you show up. This is what happens when you compare self targeting with PMT. The orange-ish yellow line is PMT and black line is self targeting and this is per capita consumption so the distribution is straight to the left. The distribution of people who are under that level probably are under 13. If you draw a vertical at 13, you hit the point at curve 6.60%. People who show up for self targeting are below 13.55%, those people who show up for the PMT are below 13. So in other words it targets strictly poor people. Let us say the people who are targeted by self targeting are strictly poor, at all points of distribution are poor people, so everywhere in the district we are getting better targeting. So self targeting strictly better targets, this is what this curve says. It is better to use the government methods. Remember we impose very little cost on them, just imagine one afternoon spent in the office. For that we get much better targeting, so that’s a good news and both inclusion and exclusion error goes down. I don’t want to spend time explaining but, so inclusion error goes down means rich don’t apply much in self targeting and poor apply more. So distribution shifts to left for both reasons, rich goes and poor comes in, so that is all good news. We try to estimate that cost by thinking of average wage of someone that is showing up, that is the cost somebody pays for spending 4 hours in the line. In those 4 hours he could have done something more productive. The cost of that we calculate is higher than the cost for the PMT. Basically in that case government pays that cost. The enumerator comes and interviews you for say 50 minutes, that is the only time you waste. The cost is in that respect higher in the government system. So if you add them up, it is clear that the net cost is low for self targeting. In that sense, self targeting is more efficient as it imposes more cost on the beneficiary but the cost to government is much lower and so the overall total cost is lower. Now one last question, as I said, would self targeting improve if we increase the cost. So one thing we did is that we randomly allocated some villages to have lower cost because they could sign up by locating right next to their house whereas in some places they had to go 3 kms away to sign up. Theory for doing MNREGA-kind of effort says bigger cost improves selection, small cost anybody can take. When the cost is higher, only those who are really desperate would be willing to pay that cost. But the answer that experience comes up with is that just about everyone drops out when you increase the distance. The poorer drops out more, the richest also drops out. So you don’t get any selection, just less people showing up. Thus it is strictly worst thing to increase the distance. Small cost thus works well and adding cost to it doesn’t help, it just gets worst selection. To summarise, community targeting did the same as government methods, slightly worse probably because government is ignoring lot of local information. Consumption indicator is not the right method necessarily. Self targeting does better than both. So if I add both these factors together, that does impose some more cost on applicants. As even in that very lucrative programme, only 60% of poorest showed up, so there is something about these programmes which is missing large part of the poorest. The open problem we have not solved not is that everyone is signing up, and if you leave on people to sign up, they don’t seem to sign up even when incentives are there. This is not an argument for moving on to NREGA type of programme, the argument is to somehow make it easier for the poorest households to sign up. How to do that is what we are working on now, how to design a programme for excluding about 40% poorest. How to bring them in is the question. This gives you a reasonable idea that self targeting is pretty effective and you can get pretty good self targeting by imposing small cost. You don’t need to show up every day> For the direct cash transfer that the government is talking about, my guess is they can do and experiment like this where you have to sign up once a month or something, just come and put in your finger print once a month and get money for whole month. I think that might be more efficient to the NREGA method of self-targeting by imposing much lower cost on people and avoiding the possibility of the poorest people also dropping out. This sort of give you a sense where this research is very much complementary to the research Professor Suresh Tendulkar was doing. Just trying the other side of it in the sense how do I design the poverty line in a way so that when you identify people below it you identify the right people. These are very complementary approaches and I am very happy to be here and speaking on this. Thank you |

Share this page:






Install the RBI mobile application and get quick access to the latest news!
Scan the QR code to install our app



Page Last Updated on:










