 IST,
IST,



Measuring Productivity at the Industry Level - The India KLEMS Database
|
AUTHORS Deb Kusum Das Abdul Azeez Erumban Suresh Aggarwal Pilu Chandra Das
Changes in India KLEMS Database 2019 over the India KLEMS 2018 version Overall changes The database is extended to include 2017-18 for all variables, thus providing a series for the period 1980-81 to 2017-18 Variable specific changes 1. Gross Value Added Estimates of Gross Value Added (GVA) for years since 2011-12, both current and constant (2011-12) prices for all industries are directly obtained from National Accounts Statistics (NAS) 2019. For years, before 2011, in India KLEMS2018 version, value added data were extrapolated backwards using annual growth rates from NAS Back Series 2011 and NAS 2014. This has now changed, as the NAS now provides Back Series with 2011-12 base. In the current version, gross value added at current prices & at constant (2011-12) prices for the period 1980-81 to 2010-11 are directly obtained from Back Series of National Accounts. 2. Gross value of Output Unlike GVA, Back Series of National Accounts (Base 2011-12) does not provide Gross Value of Output (GVO) series prior to 2011. Therefore, we estimated GVO series both at current and constant prices by applying GVO/GVA ratio from 2011 Back Series and 2014 NAS. 3. Labour Input
4. Capital Input
Intermediate input Input Output Transaction Table (IOTT) 2015-16 by Brookings India was incorporated instead of Supply Use table 2012-13. This document describes the procedures, methodologies and approaches used in constructing the India KLEMS database version 2019. This database is part of a research project, supported by the Reserve Bank of India (RBI), to analyze productivity performance in the Indian economy at disaggregate industry level. This work is meant to support empirical research in the area of economic growth. In addition, the database is meant to support the conduct of policies aimed at supporting acceleration of productivity growth in the Indian economy, requiring comprehensive measurement tools to monitor and evaluate progress. Finally, the construction of the database would also support the systematic production of reliable statistics on growth and productivity using the methodologies of national accounts and input-output analysis. In its definitive version the India KLEMS research project will include measures of economic growth, employment creation, capital formation and productivity at the industry level from 1980-81 onwards. The input measures will incorporate various categories of Capital (K), Labour (L), Energy (E), Materials (M) and Services (S) inputs. A major advantage of growth accounts is that it is embedded in a clear analytical framework rooted in production functions and the theory of economic growth. It provides a conceptual framework within which the interaction between variables can be analyzed, which is of fundamental importance for policy evaluation (Timmer et.al.2007)1. The present document describes the India KLEMS database version 2019. The present version is an extended India KLEMS research project, “Disaggregate Industry Level Productivity Analysis for India- the KLEMS Approach” being undertaken at the Centre for Development Economics, Delhi School of Economics. This one builds on the previous project, which was undertaken at ICRIER, New Delhi2. The Data Manual is intended to guide researchers about the variables (and their construction) used to measure both inputs and total factor productivity (TFP) at the industry level using the dataset. In addition, it is also intended to support national officials statistical agencies in future work on the productivity database within the agencies. The dataset includes measures of Gross Value Added (GVA), Gross Value of Output (GVO), Labour (L), Capital (K), Energy (E), Material (M), Services (S), Labour Quality (LQ), Labour Productivity (LP) and Total Factor Productivity (TFP) at the industry and economy level from 1980-81 onwards. The database covering the period 1980-81 to 2017-18 has been constructed on the basis of data compiled from CSO, NSSO, ASI, Input-Output tables (I-O tables) and processed according to appropriate procedures. These procedures were developed to ensure harmonization of the basic data, and to generate growth accounts in a consistent and uniform way. Harmonization of the basic data has focused on a number of areas such as industrial classification, and aggregation levels. The data base covers 27 industries comprising the entire Indian economy. The industries are shown in Table 1.1 below. The variables in the data set are given in Table 1.2. 1.2 Coverage: Industries and Variables In this section we describe the coverage of the India KLEMS database in terms of industries and variables. In principle, the 38 year period from 1980-81 (1980) to 2017-18 (2017) is covered. At a disaggregated level, database is created for 27 industries. The industrial classification is constructed by building concordance between NIC 2008, NIC 2004, NIC 1998, NIC 1987 and NIC 1970 so as to generate continuous time series from 1980 to 2017. This classification is very close to the International Standard Industrial Classification (ISIC) revision 3.The 27 industries are aggregated to form six broad sectors, namely:
Table 1.1 below provides a listing of the 27 industries, including the higher aggregates. Further the detailed classification and concordance of study industries with NICs is provided in Appendix table A. Table 1.2 provides an overview of all the series included in our database. Measures of Capital (K), Labour (L), Energy (E), Material (M) and Service (S) inputs as well as Gross Output (GO), have been constructed using National Accounts Statistics (NAS), Annual Survey of Industries (ASI), NSSO rounds and Input-Output Tables (IO). In building annual time series on gross output, five inputs and factor income shares, various assumptions are made to fill up gaps in industry details and link series over time. As we know that NSSO rounds of unregistered manufacturing, Input Output Transaction Tables, and Employment and Unemployment Surveys by NSSO are available only for certain benchmark years. Thus, the use of information from these data sources necessitates interpolation and assumption of constant shares for building series of output and inputs. The construction of growth accounting series like total factor productivity, labour productivity are based on theoretical models of production and needs additional assumptions that are spelt out in subsequent chapters of the manual. Finally, the other Series like NDP at factor cost, compensation of employees etc. are additional series which are used in generating the growth accounts and are informative by themselves. Chapter 2: Gross Value Added Series at the Industry Level For an individual firm or industry, productivity measure can be based on a value added concept where value added is considered as an industry’s output and only primary inputs such as labour and capital are considered as industry inputs. Value added based productivity measures reflect an industry’s capacity to contribute to economy-wide income and final demand. In this sense, they are valid complements to gross output-based measures. This chapter describes the data sources and methodology used to construct the Gross Value Added (GVA) series at current and constant prices for 27 study industries for the period of 1980-81 (1980) to 2017-18 (2017). GVA of a sector is defined as the value of output less the value of its intermediary inputs. This value added created by a sector is shared among the primary factors of production, labour and capital. The National Accounts Statistics (NAS) brought out by the CSO (Central Statistics Office, Government of India) is the basic source of data for the construction of series on gross value added for INDIA KLEMS-industries. NAS provides estimates of GVA (i.e. gross value added) at a disaggregated industry level at both current and constant prices for the period since 1950-51. Up to 2011-12, estimates of GVA at both current and constant (2011-12) prices for all industries are obtained from Back Series of National Accounts (Base 2011-12). For years after 2011-12, they are directly obtained from NAS 2019. However, NAS estimates of value added are not available for a few India KLEMS industry groups. Therefore, we had to split some of the aggregate industry groups from NAS. In the previous versions of the India KLEMS data, value-added was measured at factor cost (as was the case with the NAS), which was not fully consistent with the KLEMS standards used internationally. The new version bypasses that issue, as India's National Accounts has now entirely shifted to the basic price3 concept. Moreover, the back series of NAS are also available in basic prices, which helps us construct the entire value added series for all industries in basic price concept. NAS provides separate estimates of GVA for registered and unregistered manufacturing. However, onwards 2011-12 NAS has disaggregated the manufacturing sector in to corporate sector and household sector. For splitting the aggregate estimates of GVA for registered manufacturing industries and the corporate sector, we have used data from the Annual Survey of Industries (ASI) based on the National Industrial Classification 2004 and 2008 (NIC-2004 & NIC-2008). Whereas, for the unregistered manufacturing sector, we have used results from six rounds of NSSO surveys- [40th (1984-85), 45th round (1989-90), 51st round (1994-95) 56th round (2000-01), 62nd round (2005-06), 67th round (2010-11) and 73rd round (2015-16)] to obtain the value added estimates. In India, GDP for unregistered manufacturing is constructed using the labour input method. The estimates of GVA for the unregistered manufacturing sector are obtained as a product of the workforce and the corresponding GVA per worker. The information about employment in the unorganized sector is only available in the benchmark years for which NSSO survey data are available. Therefore, there is no consistent source of employment data for the years between these quinquennial surveys. Even the information on value added per worker is equally limited since the value-added data are also updated on an approximate 5-year interval (for details, see CSO, 2007). Therefore, estimates of value added for the unregistered manufacturing sectors for the years between the benchmarks have been obtained by interpolation and for years outside the benchmark years by linear extrapolation. For splitting the aggregate estimates of GVA for the household sector for recent years (i.e. 2011 onwards), we have used GVA data from 67th round (2010-11) and 73rd round (2015-16). The construction of Gross valued added series involves three steps. Step 1: A concordance table between the classification used in the NAS and the 27 study industry classification used for this project has been prepared. Further, concordance between all the 27 sectors has been constructed with NIC- 1970, 1987, 1998, 2004 and 2008. Out of the 27 study industries, for 20 industries, GVA series both in current and constant prices is directly available from NAS4. The sectors for which data are provided in NAS are Agriculture, Forestry & logging, Fishing, Mining and Quarrying, Manufacturing (registered and un-registered), Electricity, Construction, Trade, Hotels & Restaurants, Railways, Transport by other means, Storage, Communication, Banking & insurance, Real estate, Ownership of Dwelling & Business Services, Pubic Administration & Defense and Other Services. Step 2: For manufacturing industries where direct estimates of GVA were not available from NAS, estimates have been made using additional information from ASI and NSSO unorganized manufacturing data. For 6 out of 13 manufacturing sectors GVA data are directly available from NAS. The list of these industries is provided in the table below. For the remaining 7 industries GVA data is constructed by splitting the NAS data using ASI or NSSO distributions. ASI data (annual) has been used for registered manufacturing whereas interpolated ratios from NSSO 40th (1984-85), 45th (1989-90), 51st (1994-95), 56th (2000-01) 62nd (2005-06), 67th round (2010-11) and 73rd round (2015-16) rounds have been used for Unregistered Manufacturing segments. A list of study industries is presented in Table 2.2 showcasing the methodology used to split GVA of certain NAS sectors to match concordance with our classification. It is important to note that the industry level value added volume indices are based on NAS. CSO provides single deflated value added estimates for all sectors except Agriculture. Following are the details of steps taken in splitting NAS sectors into India KLEMS industries for which direct Gross Value Added series are not available. Wood and wood products and manufacturing of furniture In India KLEMS the sectors Wood products (20) and Furniture and fixtures (361) are considered separately, with the latter being added to the sector Manufacturing nec and Recycling (36+37). These sectors are available separately since 2011-12 from National Accounts (NAS 2019). However, the Back Series of National Accounts (Base 2011-12) does not provide them separately; rather it provides the data for the aggregate sector Wood and Wood products, furniture, fixtures etc. (20+361) – both for registered and unregistered sectors. For the registered segment of the industry, we split the value added in this aggregate sector to two individual sectors using the share of the respective sectors from the Annual Survey of Industries (ASI). For the unorganized segment, we use the shares of the respective sectors obtained from NSSO unorganized manufacturing surveys of the benchmark years (1984-85, 1989-90, 1994-95, 2000-01, 2005-06 and 2010-11), to split the aggregate data. The shares for the interim years between two benchmark years have been linearly interpolated till 2011-12, and for the period 1980-81 to 1984-85, the share of 1984-85 has been used. Coke, Refined Petroleum Products and Nuclear Fuel and Rubber and Plastic Products We split ‘Rubber, Petroleum Products’ (which are clubbed under one group in NAS) to arrive at two industry groups i.e., Coke, Refined Petroleum Products and Nuclear Fuel (23) and Rubber and Plastic Products (25). For the organized segment, we use the ASI (annual) data to get the individual sector shares and split the NAS data using these individual shares. Likewise, we use the relevant data from the four NSS surveys mentioned earlier to get the individual sector shares for the unorganized segment of this sector. The ratio of GVA for the interim years between two benchmark years have been linearly interpolated till 2011-12, and from 1980-81 to 1984-85, the ratio of 1984-85 has been used. Basic Metals and Fabricated Metal Products In our industry classification, Basic Metals and Fabricated Metal products (27+28) and Machinery (29) are separate groups whereas ‘Fabricated Metal Products’ (28); ‘Machinery and Equipment nec’ (29) and ‘Office, Accounting and Computing Machinery’ (30) are clubbed together as Metal Products and Machinery (28, 29 and 30) in NAS. To arrive at individual industry result, we use ASI shares for organized sectors and NSSO surveys for the unorganized sector. We add to the fraction of fabricated metal products (28) from Metal Products and Machinery to basic metals (271+272+2731 +2732) already available. Electrical and Optical Equipment In our study classification, ‘Electrical and Optical equipment’ includes all sectors from 30 to 33 under NIC 1998. However, ‘Electrical Machinery’ in NAS includes industries ‘Electrical Machinery and Apparatus n.e.c.’ (31) + ‘Radio, Television and Communication Equipment and Apparatus’ (32) and excludes ‘Office, Accounting and Computing Machinery’ (30) and ‘Medical, Precision and Optical Instruments’ (33). However, 30 is part of ‘Metal Products and Machinery’ and 33 is part of ‘Other Manufacturing’ in NAS. We take out 28 from Metal Products and Machinery in NAS, with 29 and 30 being left, which we split using ASI. NSSO surveys have been useful here as well to compute the unorganized segment share. Likewise, we also take out the share of 33 from ‘Other Manufacturing’ in NAS separately for both organized and unorganized segments to arrive at gross value added for electrical and optical equipment. Step 3: According to India KLEMS, output is adjusted for Financial Intermediation Services Indirectly Measured (FISIM). The value of such services forms a part of the income originating in the banking and insurance sector and, as such, is deducted from the GVA. The NAS provides output net of FISIM for some industry groups at a more aggregate level. For instance, in the estimates of GVA obtained for the registered manufacturing sector, adjustment for FISIM in NAS is made only at the aggregate level in the absence of adequate details at a disaggregate level. However, we have allocated FISIM to all the sectors of manufacturing by redistributing total FISIM across sectors proportional to their sectoral GDP shares. Similar redistribution of FISIM has been done in case of Trade sector and Other Services sector. Chapter 3: Gross Output Series at the Industry Level This chapter describes the procedures and methodologies used in constructing the database for gross output series at the industry level over the period 1980-81(1980) to 2017-18(2017). We discuss both the raw data sources and the adjustments that have been made to generate the time series on output and value added consistent with the official National Accounts. The methodology for measuring industry output, and value added was developed by Jorgenson, Gallop and Fraumeni (1987) and extended by Jorgenson (1990 a). Following a similar approach as explained in Jorgenson et al. (2005, Chapter 4) and Timmer et al. (2010, Chapter 3), the time series on gross output and intermediate inputs for the Indian economy have been constructed. The gross output of an industry is defined as the value of industry production using primary factors like labour, capital and intermediate inputs purchased from other industries. The gross output production function assumes separability in inputs and technology. An important advantage of the gross output approach is that it provides a complete measure of production and treats all inputs - labour, capital and intermediate inputs symmetrically. In contrast, the value added measure of output does not explicitly account for the flow of intermediate inputs which may be the primary component of an industry’s output. We use the more restrictive value added concept primarily because it is useful for aggregation purposes. It is to be noted that aggregate output (aggregated over industry value added), is a value added concept and the detailed methodology of aggregation of output across industries is explained in chapter 8. To construct the gross output series at industry level, we use multiple data sources namely National Accounts Statistics, Annual Survey of Industries, NSSO rounds for unorganized manufacturing and Input Output Transaction tables. The data source and methodology used are documented below: National Accounts Statistics: The NAS is the basic source of data for the construction of time series on the gross output. The NAS back series 2011 with base 2004-05 and NAS 2014 provides estimates of gross output for six disaggregate industries at current and constant prices since 1950-51 till 2011-12. These sectors are Agriculture, Mining and Quarrying, Construction and Manufacturing sectors (Registered and Unregistered Manufacturing). However, the Back Series with base 2011-12, which is the source of GVA in India KLEMS database 2019, does not provide estimates of GVO for most of the industries except for Agriculture, Mining and Quarrying and Construction. For these three industries GVO data at current and constant prices directly obtained from Back Series with base 2011-12. Therefore, for 1980-81 to 2011-12 period, we estimate the GVO series for remaining 24 industries at current and constant prices by applying the respective GVO/GVA ratio for current and constant prices obtained from Back Series with base 2004-05 and NAS 2014 to GVA with 2011-12 base. For years since 2011, we take the estimates of GVO both at current and constant prices for all industries directly from NAS 2019. (a) Filling procedures of National Accounts series: It is to be noted that the NAS estimates of gross output for a few industry groups are at a more aggregate level, requiring splitting of the aggregates. In such cases, NAS estimates of output have been split using additional information from Annual Survey of Industries and NSSO rounds of Unregistered Manufacturing to obtain estimates at higher level of disaggregation. Secondly, for Unregistered manufacturing gross output data is available in NAS from 2004-05 onwards. In this case, information from NSSO survey rounds has been used for missing years to derive output estimates of unregistered manufacturing industries at current and constant prices. Annual Survey of Industries and NSSO Quinquennial Survey Reports: As mentioned above, gross output data are available at a more disaggregated level in Annual Survey of Industries (ASI) and NSSO quinquennial surveys for Registered and Unregistered Manufacturing industries, respectively. These secondary data sources are used in this study for two purposes: (a) in certain cases NAS provides combined estimates of GVO and GVA for two manufacturing industries. In such cases separate estimates for individual study industries are obtained with the help of ASI or NSSO unorganized manufacturing sector data. (b) For the period prior to 2004, NAS does not provide estimates of GVO for unorganized manufacturing industries. To make our estimate of GVO for this period, the NSSO data are used. The Major NSSO Rounds for Unregistered Manufacturing used are 40th Round (1984-85), 45th Round (1989-90) and 51st Round (1994-95), 56th Round (2000-01), 62nd Round (2005-06), 67th Round (2010-11) and 73rd Round (2015-16). Input Output Transaction Tables: As motioned earlier, for gross value added series of service sectors we obtain our estimates from NAS. However, prior to 2011-12 National Accounts do not provide any estimates of gross output of service sectors and hence we rely on Input output transaction tables which are available at an interval of 5 years or so. This necessitates interpolation and assumption of constant shares for measuring output of services sectors. The Input Output Transaction Tables for Benchmark years of 1978-79, 1983-84, 1989-90, 1993-94, 1998-99, 2003-04 and 2007-08 are used to derive gross output series for service sectors. The construction of the gross output series from 1980 to 2017 at current and constant prices involves the following steps: Step 1: Measuring Gross Output of Agricultural Sector, of Mining and Quarrying, and Construction NAS provides nominal and real GVO series for a) Crops and Plantation, b) Animal Husbandry c) Forestry and Logging d) Fishing. By aggregating the GVO of these four subsectors we derive the GVO of Agricultural sector. The Gross output estimates of Mining and Quarrying and Construction at current and constant prices from 1980-2017 is also directly taken from NAS. Step 2: Measuring Gross Output of Manufacturing Industries For manufacturing industries time series on gross output is obtained by adding the magnitudes for registered and unregistered segments of manufacturing. As mentioned earlier, NAS estimates of gross output for manufacturing industries are at a more aggregate level. In such cases the aggregate output of NAS at current prices has been split using additional information from ASI and NSSO unorganized sector reports. Gross output data for 6 out of 13 manufacturing industries listed in table 3.1 are directly picked up from NAS. For the remaining 7 sectors output is constructed by splitting the NAS output data using ASI or NSSO distributions. ASI data (annual) has been used for registered manufacturing whereas interpolated ratios from NSSO 56th (2000-01), 62nd (2005-06), 67th (2010-11) and 73rd (2015-16) rounds have been used for Unregistered Manufacturing segments. A list of study industries is presented in Table 3.2 showcasing the methodology used to split GVO of certain NAS sectors to match concordance with our classification. The detailed method of splitting the output of NAS sectors to derive output of individual industries is given as follows: Basic Metals and Fabricated Metal Products; Machinery, nec; Electrical and Optical Equipment Metal products and Machinery of NAS is split into three parts: Fabricated Metal Products, Machinery and Equipment, Office Accounting and Computing Machinery. For registered segments individual industry shares from ASI are used to split the data. For unregistered segments sectoral shares are calculated from 56th (2000-01), 62nd (2005-06), 67th (2010-11) and 73rd (2015-16) NSSO rounds of unregistered manufacturing. The shares for interim years have been estimated by interpolation and applied to the combined output of NAS to split it into three industries. Machinery forms a separate study sector. Next, a fraction of Fabricated Metal Products is added to Basic Metals of NAS to form output for study sector Basic Metals and Fabricated Metal products. A fraction of Office Accounting and Computing Machinery is added with Electrical Machinery and Medical and Optical Instruments to form Electrical and Optical Equipment sector. Coke, Refined Petroleum Products and Nuclear Fuel; Rubber and Plastic Products We split ‘Rubber, Petroleum Products’ (which are clubbed under one group in NAS) to arrive at two industry groups, i.e., Coke, Refined Petroleum Products and Nuclear Fuel (23) and Rubber and Plastic Products (25). For the Registered segment, we use the ASI (annual) data to get the individual sector shares and split the NAS data using these individual shares. Likewise, we use the relevant data from the four NSS surveys mentioned earlier to get the individual sector shares for the unregistered segment of this sector. Wood and Products of Wood; Manufacturing nec; recycling NAS back-series 2011 (based on 2004-05 prices) provides GVO of Wood and Wood products, Furniture, Fixtures etc (20+361) for registered and unregistered manufacturing segments. Since 2004-05 (from NAS2011 onwards) we have separate series for Wood and Wood products (20) and Manufacturing of Furniture and Fixtures (361). In our study, Wood and Wood Products (20) form a separate industry. Furniture and Fixture (361) adds up with Manufacturing n.e.c5 (369) and Recycling (37) to form study industry Manufacturing n.e.c and Recycling. Thus since 2004-05, we have used the separate output series of Wood and Wood Products (20) and Furniture and Fixtures (361) obtained directly from NAS disaggregated series of registered and unregistered statement of GDP by economic activity. Prior to 2004, we use ASI data for registered segments to split the NAS sectors to arrive at estimates of individual study industry. Prior to 2004, we observed some fluctuation in the estimated GVO series for Manufacturing nec; Recycling industry. We tried to correct that by applying GVO to GVA ratio to GVA estimates. These ratios are separately obtained from ASI and NSSO survey rounds and then combined using organized and unorganized industry share in aggregate value added. However, for the period prior to 2004, separate output estimates for unregistered manufacturing segments are not available in NAS. Thus, to estimate output of unregistered manufacturing for the period 1980 to 2003 the following has been done.
Step 3: Measuring Gross Output for Services Sectors and Electricity, Gas and water supply Onwards 2011 -12 NAS provided estimates of GVO at current and constant prices. Prior to 2011-12 Gross Output series for Services sectors and sector Electricity, Gas and Water supply has been constructed using information from Input – Output Transaction Tables of the Indian economy published by CSO.
Firstly, the present study provides estimates for manufacturing and its sub branches without segregating manufacturing (and its sub branches) into organized and unorganized segments. However, given the employment potential and sizable presence of the unorganized segment in many of the manufacturing industries, it would be worthwhile in Indian context to examine separately the productivity performances of both the organized and unorganized components. Some work to construct the output and input series separately for organized and unorganized components of Indian manufacturing has been done. A paper based on this analysis has been prepared. The data series for organized and unorganized manufacturing is not included in this release of India KLEMS database. Finally, National Accounts do not provide any estimates of gross output of services sector and hence we rely on Input output transaction tables which are available at an interval of about 5 years. This necessitates interpolation and assumption of constant shares for measuring output of services sectors. This issue is analogous to those explained in Timmer et al. (2010, Chapter 3) for the EU economy. Griliches (1994) paid particular attention to service sector output as a key source of uncertainty. Chapter 4: Labour Input Series at the Industry Level This chapter provides information on the sources of data and method of measuring labour services. The aim is to estimate labour input so that it reflects the actual changes in the quantity (number of persons) and quality of labour input over time. 4.1 Data Source, and Methodology The section discusses the construction of labour input for 27 industries from 1980 to 2017. Labour input is measured by combining data on labour persons and data on labour quality. In the KLEMS framework it is desirable to estimate changes in labour quality by industries on the basis of age, gender and education. The measurement of labour quality is essentially an attempt to distinguish one labour type from the other taking into account the embodied human capital in each person. The source of human capital could be through investment in education, experience, training, etc. The contribution to output by each person also comes from this embodied capital and the reward (wages and earnings) to each person also includes the reward for investment in human capital. Therefore, it is essential to separate out these differences in labour to clearly understand the underlying differences in labour characteristics. It is in this context that an endeavor has been made to estimate labour quality index. Nevertheless, many limitations of India’s employment statistics, especially the availability of information on wages/ earnings of different category of workers which could be used as an indication of their differences in ability makes it difficult to quantify these changes in the labour force in a pertinent way. Therefore, the study has computed the labour quality index based on five different education categories only. The problems of employment statistics in India have been widely discussed in the literature (Sivasubramonian; 2004, & Himanshu; 2011, Ghose; 2016). This study aims to build a time series of employment series for 27 industrial sectors. However, there exists no time-series data on Indian economy, except for the organized segment. Therefore, it was essential to make certain assumptions regarding the annual changes in the employment series using available information. In this section we outline the sources of data and the methodology used. The section develops and implements the methodology of estimating persons employed (employment) and labour quality and combining the two to obtain the indices of labour input. Sources of data The Employment and Unemployment Surveys (EUS) of major rounds from 38th round (1983) to 68th round (2011-12) and the Periodic Labour Force Survey (PLFS) of 2017-18 by National Sample Survey Office (NSSO) are the main sources for estimating the total workforce in the country by industry groups, as per the National Industrial Classification (NIC). The estimates obtained from EUS are adjusted for population. The major round 32nd (1977-78) has been used for extrapolating the labour series to 1980-816. The source of data for the population is Census of India (different years), which only gives decadal census, so interpolated mid-year population is used for intervening years. In the EUS, the persons employed are classified on the basis of their activity status into usual principal status (UPS), usual principal and subsidiary status (UPSS), current weekly status (CWS) and current daily status (CDS) for quinquennial rounds. UPSS is the most liberal and widely used of these concepts and despite that the UPSS has some limitations7, this seems to be the best measure to use given the data. Methodology a) Measuring persons employed at the Industry Level Efforts are made in this section to describe the methodology used to estimate persons employed by 27 industry and for broad sectors and adjust that measure for changes in labour skill by calculating the labour quality index, thus obtaining the quality corrected labour input. Since NSSO uses National Industrial Classification 1970 (NIC) for classification of persons employed by industry in 38th and 43rd rounds, NIC 1987 for 50th round, NIC 1998 for 55th and 61st rounds, and NIC 2008 for 68th round and PLFS, therefore as a starting point concordance between the 27 sectors, and NIC-1970, 1987, 1998 and 2008 was done. The underlying methodological issue is how to estimate number of persons employed. In India, the total workforce in the country and its distribution over economic activities may be obtained from the decennial Population Census and the Employment and Unemployment Surveys (EUS) of the NSSO8. Out of the two, the latter are more dependable and have been used to assess the changes in employment and unemployment for employment planning and policy analysis. The preference for the use of EUS is generally based on the notion that prior to 2001, the three Censuses have clearly under reported the participation of women in economic activities; whereas the EUS has provided reasonably reliable estimates of the level and pattern of employment (Visaria; 1996). While Population Census underestimates work force participation rates (WPRs), the EUS estimates of total population are significantly lower than the Population Census based estimates – by over 20 percent in Urban India9. However, for the Census 2001, the WFPRs are closer to the rates from the 1999-2000 NSSO round. Due to these advantages of EUS, the present study has used the major rounds of EUS10 for the years till 2017-18. Thus, the surveys used are 38th, 43rd, 50th 55th, 61st, 68th rounds and PLFS11. The employment in India has then been computed step-wise as follows:
For extrapolation backward to 1980-81 to 1982-83, the interpolation of the broad industrial classification of 32nd round (1977-78) and 38thround (1983-84) is used. Thus, the estimates from 32nd round are mainly used as control numbers. Between the survey periods interpolation of estimates was done to find employment for the intervening period. However, in few survey periods where the disaggregate employment of an industry was an outlier, it was ignored for interpolation and the interpolation in such cases was done between the other two adjacent rounds. The interpolation was supplemented by data from Economic Survey and ASI also. The growth rates, since 1984-85, from Economic Survey data has been used for the two industries- Electricity, Gas & Water Supply; and Public Administration and Defense- where public sector mainly dominates. Similarly, the growth in employment, since 1984-85, in the two other industries-Coke, Refined Petroleum products; and Transport Equipment, where a large proportion of employment is in the organized sector is taken from ASI. The current employment series thus makes use of all the different available sources of data on employment to obtain a smooth and long time series which captures the relevant information provided by these sources. Between 2005 and 2011, we observed very high growth rate in number of employed persons series for the industry Electrical and Optical Equipment as compared to other manufacturing industries and the overall growth in employment in this industry during 2005-2011 was found to be higher than that for Construction (which seems somewhat unrealistic). It was also observed that there was a negative growth in employment in Textiles, Textile Products, Leather and Footwear although real GVA of this industry more than doubled between 2005 and 2011. To address these issues, some adjustments to the initial employment estimates for Electrical & Optical Equipment and Textiles, Textile Products, Leather and Footwear have been done. Onwards 2005, employment series for Electrical & Optical Equipment has been estimated applying annual growth rates obtained from ASI and NSSO rounds to the number of employed persons for the year 2005-06. Then, for the years 2005-06 to 2011-12, we compute the difference between estimated employment series from EUS rounds and that based on ASI & NSSO rounds for the Electrical and Optical Equipment industry and add it to Textiles, Textile Products, Leather and Footwear industry. This ensures that for the manufacturing as a whole our estimates remain the same as obtained from EUS rounds. Measuring quality index The quality of labour force is of considerable importance in the context of productivity measurement, and one of the widely used methodologies to capture changes in labour quality is given by Jorgenson, Gollop and Fraumeni (JGF) (1987). In growth accounting methodology of measurement of total factor productivity (TFP) when output growth is decomposed in to growth of inputs and the residual TFP, then labour input is measured as an index of labour service flows. It accounts for changes in labour quality in terms of labour characteristics such as educational attainment, age (experience), gender, employment status, etc. and thus accounts for heterogeneity of the labour force. In this method the aggregate labour input Lj of sector ‘j’ is defined as a Törnqvist volume indexof persons worked by individual labour types ‘l’ as follows:13   The first term on the right-hand side Δ ln LCj indicates the change in labour quality and the second term indicates the change in total persons employed in sector ‘j’. It can easily be seen that if proportions of each labour type in the labour force change, this will have an impact on the growth of labour input beyond any change in total persons worked. The index of aggregate (or grand) labour quality thus measures the changes in the sex-age-education-occupation quality of the economy. However, the use of this method is data intensive. There is a second approach to the measurement of skill levels. The procedure is to use a simple index of educational attainment to adjust for skill differences. So, improvement in educational attainment is adjusted by incorporating average years of schooling as the proxy for skill levels.For example, an index of the form: L* = easL assumes that each year of schoolings, raises the average worker’s productivity by a constant percentage, ‘a’. Such studies have been carried out for different time periods and for a large number of countries around the world, typically finding a return to each additional year of education in the range of 7 to 12 percent (BCV, 2007). This approach however does not distinguish between the return to different levels of education and provides a single uniform rate for all the years of education. Bosworth and Collins (2008) assumed a constant annual return of 7 percent for each additional year of education irrespective of the level of education. Another problem with the assumption of uniform returns for each year of education is that it ignores all other variations-, over gender, over age groups, over industries, etc. and only includes education. It is thus not able to capture the impact of change in gender composition, age composition (a proxy for experience), employment status, and industry composition, etc. There are however, also disagreements on the use of JGF methodology, especially in the Indian context, as it assumes the existence of perfectly competitive labour markets where wage rate is the indicator of a person’s marginal productivity. The analysts argue that the observed wage differences may reflect factors other than productivity differences. Its use is also questioned because data for large segment of Indian labour force- the self -employed is not available. Since the Indian labour market is still not very competitive and there are data weaknesses, therefore the researchers in India have generally avoided applying the JGF methodology. For this reason, most Indian researchers have also avoided to account for the differences in age and gender characteristics. However, to account for educational differences they have preferred to exercise either of the two choices- one to use Barrow and Lee (1993) methodology and presume a constant rate of return for education (BCV, 2007) or second is to use the limited information available on wages for few rounds and only for casual and regular employees (Sivasubramonian, 2004) to determine the relative weights for different types of persons. Due to data limitation of sample size becoming very small as we try to estimate persons employed and earnings by industry by all the characteristics15, the present study has computed labour quality index by using only education characteristic in the JGF methodology. For labour quality index the data thus required is employment by education, by industry, and earnings (compensation) for each cell. The labour quality index16 has been computed using five education categories17 namely- up to primary, primary, middle, secondary & higher secondary, and above higher secondary18. There are thus five types of persons employed for each of the 27 study industries. The quality index is estimated for total persons employed in these industries in India for the 38th, 50th, 55th, 61st, 68th and PLFS rounds of NSSO with 1983 (38th round) as the base, so as to assess the temporal changes in labour skill. Since the series is required from 1980-81, we have extrapolated it backwards from 1983 and interpolated between the major rounds. The quality index is recomputed with base 1980 as 100. Therefore, the following steps have been performed:
Once the above steps are taken to find out educational distribution of all employed persons in all the selected rounds and their corresponding wages, the computation of the labour quality index is carried out. The index so computed is basically an education composition index because it is based on only one labour characteristic, namely education and ignores others like gender, age, etc. The labour input (adjusted labour persons) then can be obtained by multiplying the number of persons employed by the corresponding labour quality index and the labour input growth is finally obtained by combining the growth of persons employed and the growth in the index of labour quality. Appendix C: Definitions of Employment in NSSO employment & unemployment surveys The surveys of NSSO on employment and unemployment (EUS) aim to measure the extent of ‘employment’ and ‘unemployment’ in quantitative terms disaggregated by various household and population characteristics following the three reference periods of (i) one year, (ii) one week, and (iii) each day of the week. Based on these three reference periods three different measures, termed as usual status, current weekly status, and the current daily status, are arrived at. While all these three approaches are used for collection of data on employment and unemployment in the quinquennial surveys, the first two approaches only are used for the purpose in the annual surveys. Usual principal status: In NSS 27th round, the usual principal activity category of the persons was determined by considering the normal working pattern, i.e., the activity pursued by them over a long period in the past and which was likely to continue in the future. For the identification of the usual principal status of an individual based on the major time criterion, in NSS 27th, 32nd, 38th, 43rd rounds, a trichotomous classification of the population was followed, that is, a person was classified into one of the three broad groups ‘employed’, ‘unemployed’ and ‘out of labour force’ based on the major time criterion. From NSS 50th round onwards, the procedure was changed and the prescribed procedure was a two stage dichotomous one which involved a classification into ‘labour force’ and ‘out labour force’ in the first stage, and thereafter, the labour force into ‘employed’ and ‘unemployed’ in the second stage. Usual subsidiary status: In the usual status approach, besides principal status, information in respect of subsidiary economic status of an individual was collected in all employment and unemployment surveys. For deciding the subsidiary economic status of an individual, no minimum number of days of work during the last 365 days was mentioned prior to NSS 61st round. In NSS 61st round, a minimum of 30 days of work, among other things, during the last 365 days, was considered necessary for classification as usual subsidiary economic activity of an individual. Current weekly status: It is important to note at the beginning that in the EUS of NSSO, a person is considered as worker if he/she has performed any economic activity at least for one hour on any day of the reference week and uses the priority criteria in assigning work activity status. This definition is consistent with the ILO convention and used by most of the countries in the world for their labour force surveys. In NSSO, prior to NSS 50th round and in all the annual surveys till NSS 59th round, data on employment and unemployment in the CWS approach was collected by putting a single-shot question ‘whether worked for at least one hour on any day during the last 7 days preceding the date of survey’. The information so collected was used to determine the CWS of the individuals. This procedure was criticized for being not able to identify the entire workforce, particularly among the women. It was then decided to derive the CWS of a person from the time disposition of the household members for the 7 days preceding the date of survey. The procedure was used for the first time in NSS 50th round. It is seen that the change in the method of determining the current weekly activity had resulted in increasing the WPR in current weekly status approach - more so for the females in both rural and urban areas than for males. The trend observed in NSS 50th round in respect of the WPR according to CWS suggested continuing with the procedure for data collection in CWS in NSS 55th and NSS 61st rounds. Current Daily Status Current Daily Status (CDS) rates are used for studying intensity of work. These are computed on the basis of the information on employment and unemployment recorded for the 14 half days of the reference week. The employment statuses during the seven days are recorded in terms of half or full intensities. An hour or more but less than four hours is taken as half intensity and four hours or more is taken as full intensity. An advantage of this approach was that it was based on more complete information; it embodied the time utilisation, and did not accord priority to labour force over outside the labour force or work over unemployment, except in marginal cases. A disadvantage was that it related to person-days, not persons. Hence it had to be used with some caution.
Chapter 5: Capital Input Series at the Industry Level This chapter outlines the methodology employed to estimate capital services for the 27 industries in the India KLEMS database version 2019. Following an overview of the theoretical method developed by Jorgenson and Griliches (1967), and outlined in Jorgenson, Gollop and Fraumeni, (JGF, 1987), the chapter discusses the specific empirical approaches we follow to implement these methods within the constraints of data availability for Indian industries. For the measurement of capital services, we need capital stock estimates for detailed asset types and the shares of each of these assets in total capital remuneration. Using the Törnqvist approximation to the continuous Divisia index under the assumption of instantaneous adjustability of capital, aggregate capital services growth rate is derived as a weighted growth rate of individual capital assets, the weights being the compensation shares of each asset, i.e.   Since our measure of capital input takes account of asset heterogeneity, it was essential to obtain investment data by asset type. We distinguish between 3 different asset types – construction, transport equipment, and machinery (includes ICT and non-ICT machinery).24 We exploit multiple sources of information for the construction of our database on capital services. This includes the National Accounts Statistics (NAS) that provide information on broad sectors of the economy, the Annual Survey of Industries (ASI) covering the organized manufacturing sector, the National Sample Survey Office (NSSO) rounds for unorganized manufacturing and Input-Output tables. Even though we use multiple sources of data, our final estimates are fully consistent with the aggregate data obtained from the NAS. In addition, our approach to capital measurement is consistent with international practices such as the EU KLEMS25, which ensures the possibility of international comparisons. In what follows, we discuss the various sources of data for asset wise investment and the construction of the relevant variables, in detail. (a) Asset-wise investment for broad sectors of the economy Industry-level estimates of capital input require detailed asset-by-industry investment matrices. NAS provides information on aggregate capital formation by industry of use for 9 broad sectors, which, nevertheless, was not sufficient for our purpose. Therefore, we have collected more detailed data on assets and industries from the CSO.26 This is the data underlying the published aggregate gross fixed capital formation by the broad industry groups, separately for public and private sectors. For those sectors for which the investment matrices were not available from CSO, we gather information from other sources (e.g. ASI for organized manufacturing and NSSO surveys for unorganized manufacturing) and benchmark it to the aggregate investment series from the National Accounts. The data used in the current version of the India KLEMS is based on the revised NAS with 2011-2012 base, and is available only since 2012. Therefore, for earlier years, we extrapolate the series using growth rates from previous version of the data. However, there were slight differences between the industry groups available in the current release of the NAS data and the previous ones (see Table 5.1), which required some matching of sectors before combining the two series. Table 5.2 provides an overview of asset types available in NAS and their corresponding asset types used in our study. Investment in education and health are obtained directly from national accounts for the period after 2012, for each asset. For years before 2012, we assume the trend in the distribution of output, in order to split the total investment in the aggregates of these sectors into sub-sectors.
Total investment in each asset category is calculated as the sum of private and public sector investment in each asset. Investment in transport equipment is not available separately for private sector. We tried several approaches to impute the private sector transport equipment data. The first was to use the share of transport equipment in non-departmental enterprises. More specifically, we apply the non-departmental enterprise transport equipment to machinery & equipment (including transport equipment) ratio to machinery & equipment in private sector for each industry to obtain industry wise transport equipment for private sector. We take non-departmental enterprise only, rather than the entire public sector, as it may be more realistic as it consists of public sector companies and statutory corporations, excluding administrative sector. However, the sum of industry estimates generated by this approach was not consistent with the reported aggregate private sector transport equipment. Therefore, we take a second step here, which is to use the industry distribution from this series and apply it to the published total private sector transport equipment data. The estimated transport equipment is then subtracted from each industry’s total machinery & transport equipment data, to obtain machinery in private sector as a residual. However, this approach generates many negative numbers in transport equipment in private sector, particularly in transport services. Therefore, we follow a third approach, which is what we finally use in the database. We first distribute the NAS total machinery in the private sector using the industry distribution of machinery and transport equipment. These estimates are then subtracted from each industry’s total machinery & transport equipment data to obtain the transport equipment investment in the private sector industries. The capital data for 2017-2018 required an additional assumption. Since we did not obtain detailed asset/industry-wise data on capital formation from the CSO, as in the past, for constructing 2017-2018 update, we relied solely on publicly available data from the National Accounts. The publicly available data contains more detailed information now, compared to what it used to be in the past. Therefore, the reliance on the NAS public data did not create too many challenges. However, there was one outstanding issue. The asset transport equipment was not separately available in this data. Therefore, we assumed the share of transport equipment in the total machinery and equipment group in 2016-2017 to remain constant to create nominal investment in transport equipment in 2017-2018. The nominal investment was deflated using GFCF deflator for transport equipment (see section (c)). (b) Asset-wise investment for non-NAS sectors NAS provides data only for 9 broad sectors, while we have 27 industries, which necessitated further splitting of some of the NAS sectors. This includes aggregate manufacturing (registered and unregistered separately) with 13 sub sectors; other services into 4 sub sectors; and real estate activities and business services into 2 sub sectors. The manufacturing sector investment data was disaggregated into 13 subsectors at the 2 digit level of NIC 1998 using ASI and NSSO data, which will be discussed in detail subsequently. Investment series in service sector has been split into sub sectors using two alternative approaches–value added shares, and capital/labour ratio in the higher aggregate industry. However, the final data used are based on value added shares, as a sensitivity analysis did not show a significant difference between the two. In order to split the aggregate capital formation in organized manufacturing sector into 13 study sectors, we use the Annual Survey of Industries. However, the published data does not provide any asset wise investment information; it consists of only the aggregate capital formation or the book value of fixed capital. Most studies in the past have measured gross investment as the difference between book value of asset in period t and in period t-1 and add depreciation in period t to that. This approach has the deficiency of comparing two different samples reported in two different years, where the number of firms/factories might be different. In particular, while using this approach at industry level, for detailed asset categories, it might generate massive negative investment. We follow an alternative approach, following ASI’s definition of gross fixed capital formation (GFCF). ASI defines GFCF as actual additions (newly purchased, second hand and own construction) minus deductions plus depreciation adjustment for discarded assets during the year. This approach is based on a single year’s sample and helps to avoid potential huge negative investment series, and is also consistent with published ASI GFCF series. The yearly detailed volumes beginning 1964-65 were used to derive the gross fixed capital formation by asset type directly. For the years 1964-1978, the relevant data are obtained from published detailed volumes. For the period, 1983-84 to 2004-05 ASI has generated detailed tables from Block C of ASI schedule that contain data on fixed assets. Data for missing years are interpolated using the changes in investment using book value method. Table 5.3 provides an overview of the asset categories available in ASI, and the relevant asset categories in our study to which they are attributed. Though ASI provides investment in land, for reasons of NAS consistency we exclude it from our database. Once investment in each of these assets and industries are generated using ASI data, we apply this industry-asset distribution to the published aggregate NAS GFCF series for organized manufacturing sector. It may also be noted that from 1960-61 to 1971-72, ASI data are for the census sector and from 1973-74 onwards they are for the factory sector. In order to make these two series comparable over years, we convert the data prior to 1972 to factory sector using the factory/census ratio in 1973. Thus, after these adjustments, we obtain investment data for 13 manufacturing sectors, by asset types, consistent with the NAS aggregate. The data required for creating the gross investment series for the 13 sectors of the unorganized manufacturing sector are obtained from various rounds of NSSO surveys on unorganized manufacturing. We use 6 rounds of NSSO surveys that cover the period 1989-2016. These are 45th round (1989-90), 51st round (1994-94), 56th round (2000-01), 62nd round (2005-06), 67th round (2010-11) and 73rd round (2015-16). Unit level data has been aggregated to 13 industries using the appropriate concordance tables. NSSO provides net addition to owned assets during the reference year within the block of fixed assets, and we use this as a measure of our investment. Asset classification in NSSO has changed over various rounds, and therefore, we have tried to match these with our classification as shown in Table 5.4. The investment series arrived at for six rounds were interpolated to obtain the annual time series of unorganized gross fixed capital formation by asset type. As in the case of registered sector, once the investment by asset types across industries are constructed, the asset-industry distribution is applied to the published NAS aggregate GFCF in unregistered manufacturing to obtain NAS consistent GFCF by asset type and industries. (c) Investment Prices by Asset Types In order to compute asset wise capital stock using PIM (equation 5.3) and rental price (equation 5.4), we require asset wise investment price deflators. Since CSO has provided us with investment data by industries and assets both in current and constant prices, we could derive the price deflators with base 2011-2012. For years before 2011, prices were spliced using 2004-2005 base investment deflators. These deflators are directly used for all the three asset categories we have. Since there was no separate asset wise data available for transport equipment in 2017-2018, the investment deflator for transport equipment from 2016-2017 was extrapolated using the trend in the investment price of total machinery & equipment, obtained from NAS. (d) Initial Stock, Depreciation Rates and Rate of Return As is evident from equations 5.1 to 5.4, our estimates of capital input require time-series data on asset wise capital stock. Capital stock has been constructed using perpetual inventory method (PIM), where the capital stock (S) is defined as a weighted sum of past investments with weights given by the relative efficiencies of capital goods at different ages, which requires data on current investment by asset types, investment prices by asset types and depreciation rate. Also, for the practical implementation of PIM to estimate asset wise capital stock, we require an estimate of initial benchmark stock (see Erumban, 2008b for an in-depth discussion on this issue). NAS provides estimates of net capital stock since 1950 for all the broad sectors in its Statement 17: Net Fixed Capital Stock by industry of use. We take the NAS estimate of real net capital stock in 1950 (in 1999-2000 prices) as our benchmark stock for all non-manufacturing sectors, and for manufacturing sectors the same is taken for the year 1964.28 However, since the NAS estimate is available only for broad sectors and for aggregate capital, we use our industry-asset distribution of GFCF in order to create net fixed capital stock estimates by asset type for all the 27 sectors. NAS also provides detailed tables on assumed life of assets used for computing capital stock, for private units, administrative units as well as departmental and non-departmental units by asset types.29 We use these estimates of lifetime to derive appropriate depreciation rates for non-ICT assets, using a double declining balance rate. Following the NAS, we assume 80 years of lifetime for buildings, 20 years for transport equipment, and 25 years for machinery and equipment (see Appendix 26.2; CSO, 2007). The final depreciation rates used in the study are given in Table 5.5 by asset type. Subsequently, we build our capital stock series by asset types for all the 27 industries using our GFCF series from 1950 (1964) onwards for the non-manufacturing (manufacturing) sectors. Our measure of capital input is arrived using equation (5.1), for which we also require estimates of rental prices (see equation 5.4). Assuming that the flow of capital services is proportional to the capital stock at individual asset level, aggregate capital flows can be obtained using a translog quantity index by weighting growth in the stock of each asset by the average shares of each asset in the value of capital compensation, as in (5.1). The rate of return (i) in equation (5.4) represents the opportunity cost of capital, and can be measured either as internal (or ex post) rate of return, or as an external (ex ante) rate of return.30 This issue will be addressed in the further revisions of the data. The present version of the database uses an external rate of return, proxied by average of return on government securities and prime lending rate obtained from the Reserve Bank of India31. Therefore, we use a real rate, which is net of capital gain. Hence, the capital gain component in equation (5.4) is excluded while estimating rental price using external rate of return, obtaining  Where i* is the real rate of return, nominal interest rate adjusted for CPI inflation rate. Chapter 6: Intermediate Input Series at the Industry Level In this section, we describe the basic approach we have used to derive the volume series of Intermediate Inputs namely –Energy input (E), Material input (M) and Services input (S). This breakdown of intermediate inputs can be used for extending the growth accounting exercises, but also convey interesting information about changing pattern in intermediate consumption (see e.g. JHS 2005, chapter 4) The methodology for measuring industry output, intermediate inputs and value added was developed by Jorgenson, Gallop and Fraumeni (1987) and extended by Jorgenson (1990 a). The cornerstone of this approach is a time series of input output (IO) tables which gives the flows of all commodities in the economy, as well as payments to primary factors. Every commodity is accounted for, whether produced by a domestic source or imported, and every use is noted, whether purchased by an industry or by a final demand element. All payments to factors of production i.e. labour and capital is accounted for so that all income elements of GDP are included. The methodology of constructing time series on energy, material and services inputs for the European economy has been elucidated in Timmer et al. (2010, Chapter 3). Following a similar approach as explained in Jorgenson et al. (2005, Chapter 4) and Timmer et al. (2010, Chapter 3), the time series on intermediate inputs for the India KLEMS project have been constructed. Definition of EMS: As in EU KLEMS, this study identifies three main categories of Intermediate inputs. They are classified as follows:
Intermediate Inputs are broken down into energy, material and services, based on input output transaction tables using a standard NIC product classification. The following five energy types (and products) have been classified as the Energy input.
The following fourteen input items have been classified as the Service input
All other intermediate inputs barring the above mentioned nineteen inputs are classified as material input. The key building block for constructing time series on Intermediate Inputs at current prices, as explained in Jorgenson et al. (2005, Chapter 4), is the input-output transaction tables, that is, the inter industry transaction tables that provide a description of which industries produce each product and which industries use them. The input-output table gives the inter-industry transactions in value terms at factor cost presented in the form of commodity x industry matrix where the columns represent the industries and the rows as group of commodities, which are the principal products of the corresponding industries. Each row of the matrix shows in the relevant columns, the deliveries of the total output of the commodities to the different industries for intermediate consumption and final use. The entries read down industry columns give the commodity inputs of raw-materials and services, which are used to produce outputs of particular industries. The column entries at the bottom of the table give net indirect taxes (NIT) (indirect taxes – subsidies) on the inputs and the primary inputs (income from use of labour and capital), i.e., Gross Value Added (GVA). As the IOTT is in the form of commodity x industry matrix, the row totals do not tally with the column totals. The difference between each column and the corresponding row totals is due to the inclusion of the secondary products, which appear particularly in the case of manufacturing industries. This is so because by-products are also manufactured by industries in addition to their main products. Thus, while determining the entries in the rows, a by-product of an industry is transferred to the sector (commodity row), whose principal product is the same as the by-product under reference. The columns, however, show the total of principal products and by-products of each industry. All the entries in the IOTT are at factor cost, i.e. excluding trade and transport charges and NIT. The Input Flow Matrix at factor cost, published by CSO, for 1978 is a 60 x 60 matrix. The absorption matrices for 1983, 1989, 1993 and 1998 have 115 sectors. However, a detailed 130 sector absorption (commodity x industry) matrix for the Indian economy has been published from 2003-04 onwards. The scheme of sector classification adopted in IOTT 2015-1632, IOTT 2007-08 and IOTT 2003-04 vis-à-vis, IOTT 1983-84, IOTT 1989-90, IOTT 1993-94 and 1998-99 has undergone significant change with the disaggregation of some of the sectors, which have become significant in early 2000s.
The methodology for computation of Intermediate Input Series for 27 Industries from 1980-2016 at current and constant prices is explained in steps. Step 1: Concordance is done between IOTT and study industries
Step 2: Obtaining estimates for Material, Energy and Service Inputs for 27 Industries, in benchmark years
Thus, for each of the benchmark year, estimates are obtained for Material, Energy and Service Inputs that has been used to produce Gross output in the 27 different India KLEMS Industries. Step 3: Projecting a time series (1980 to 2015) of proportions of Material, Energy and Service Inputs in Total Intermediate Inputs for each of the 27 industries
There exists some abnormal fluctuation in the proportions of Material Inputs, Energy Inputs, and Service Inputs in Total Intermediate Inputs for benchmark years. In that case, we drop that specific benchmark proportion and linearly interpolate of the adjacent benchmark proportions to estimate proportion for intervening years. For the industry ‘Wood & Wood Products’, we estimated proportions of Material Inputs, Energy Inputs, and Service Inputs in Total Intermediate Inputs from SUT 2015-16 instead of Input Output Transaction Table 2015-16. This has been done because the relevant proportions in SUT 2015-16 is believed to be making a more correct assessment. For the industry group ‘Coke, Refined Petroleum and Nuclear Fuel’, we estimated proportions of Material Inputs, Energy Inputs, and Service Inputs in Total Intermediate Inputs from ASI data instead of Input Output Transaction Table. This has been done because the relevant proportions differed significantly between the input-out tables and ASI, and the latter is believed to be making a more correct assessment of energy inputs used in the Coke and Petroleum products industry. For example, coal consumed in the Coke industry is taken primarily as material rather than energy. From IOTT it is difficult to estimate how much of coal consumption is for energy purposes and how much as material input, where ASI provides details information about energy consumption by energy inputs like: coal, electricity, petroleum and others including natural gas. Step 4: Consistency with NAS The projection of intermediate input vector, using IOTT in Step 3 needs to be consistent with the estimated output from NAS.
1. For Benchmark years: Ratio of Total Intermediate inputs from NAS to that from IOTT is adjusted proportionately to the absolute value of Energy Inputs/Material Inputs/Service Inputs obtained from IOTT. 2. For Intervening Years: The interpolated proportions of Energy Inputs, Material Inputs and Services Inputs obtained from IOTT, is applied directly to the total intermediate inputs from NAS to get each inputs share. Two examples have been given below for the Construction sector: In the examples above, we can see that the total value of intermediate input exactly matches the gap between Gross output and Value added. Similar adjustments have been made to construct the input series for all the other 27 study industries from 1980-2017. For every benchmark year where IOTT is available adjustment ‘A’ has been done. For every non-benchmark year, where IOTT is not available and an intermediate input vector has been projected, adjustment ‘B’ has been done to generate the comprehensive time series of Intermediate inputs consistent with the official National Accounts. Steps 1-4: This gives a time series of Material, Energy, and Service Inputs for 27 study Industries from 1980 to 2017 at current prices. Steps 5 and 6 below, explain the methodology for computation of Intermediate Input Series for 27 study Industries from 1980-2017 at constant price. The approach followed here is to first form the aggregates of materials, energy and services at current price for each study industry from the benchmark Input Output tables and then develop deflators of Materials, Energy and Service Inputs for each of the 27 study Industries separately. Step 5: Constructing Deflators of Materials, Energy and Service Inputs for 27 study Industries separately
Step 6: Computing Time Series on Intermediate Input for 27 study Industries from 1980-2014, Constant prices
Thus, we have a time series of Material, Energy and Service Inputs for 27 study Industries at constant prices. Firstly, input output transaction tables are generally available on a five year interval period and this necessitates interpolation and assumption of constant shares in some cases, to construct the entire time series of EMS from 1980 to 2017. Secondly, unlike studies using detailed survey data, we have to assume that all buyers pay the same price for each commodity because there is no information about price divergences. Thirdly, the estimated time series of Intermediate Inputs at constant price will not be consistent with the intermediate input of NAS at constant price i.e. the deflated value of intermediate input cannot match the gap between value added and gross output at constant price from NAS. This is because; NAS uses a single deflation method to estimate Gross Value Added and Gross Output at constant price. Chapter 7: Factor Income Share Series at the Industry Level The distribution of income between capital, labour and intermediate inputs, is an important element in growth accounting because income shares, under conditions of competitive markets, can be used to measure the contributions each factor makes towards output growth. 7.1 Methodology for Measuring Labour Income Share Series Under the assumption of constant returns to scale with two factors of production i.e., labour and capital, the sum of the labour income share and capital income share is 1. The labour income share is defined as the ratio of labour income to GVA. Capital income share is accordingly obtained as one minus labour income share. There are no published data on factor income shares in Indian economy at a detailed disaggregate level. National Accounts Statistics (NAS) of the CSO publishes the NDP series comprising of compensation of employees (CE), operating surplus (OS) and mixed income (MI) for the NAS industries. The income of the self-employed persons, i.e. mixed income (MI) is not separated into the labour component and capital component of the income. Therefore, to compute the labour income share out of value added, one has to take the sum of the compensation of employees and that part of the mixed income which are wages for labour. The computation of labour income share for the 27 study industries involves two steps. First, estimates of CE, OS and MI have to be obtained for each of the 27 study industries from the NAS data which are available only for the NAS sectors (see Table 7.1). Second, the estimate of mixed income has to be split into labour income and capital income for each industry for each year (except for those industries for which the reported mixed income is zero, for instance, public administration). Basis data sources used for the computation of labour income share are NAS, ASI and unit level data of survey of unorganized manufacturing enterprises. These data sources are used to obtain estimates of CE, OS and MI for each of the 27 study industries. For splitting the labour and non-labour components out of the mixed income of self-employed, the unit level data of NSS employment-unemployment survey are used along with the estimates of CE, OS and MI basically obtained from the NAS. a) Construction of Labour Income Share Series in Gross Value Added The estimation of labour income share for the 27 study industries has been done in two steps, as discussed below. Step 1: Estimation of CE, OS and MI for the 27 study Industries NAS provides estimates of compensation of employees (CE), operating surplus (OS) and mixed income (MI) for the 9 NAS industries in different annual Sequence of National Accounts reports. In the Back Series with base 2011-12, NAS updated the estimates of GVA for the years prior to 2011-12, but did not provides the updated estimates of CE, OS and MI. Therefore, for 1980-81 to 2011-12 period, we proportionally adjusted the CE, OS and MI series corresponding to the updated GVA estimates. For some industries under study, for instance (i) Agriculture, forestry & logging and fishing, (ii) Mining & Quarrying, (iii) Electricity, gas and water supply and (iv) Construction, the required data are readily available from NAS. For others, the estimates available in NAS have to be distributed across the study industries. In certain cases, the estimates of CE, OS and MI for a particular NAS sector have been distributed across constituent study industries proportionately in accordance with the gross value added in those industries. Estimate of factor incomes for ‘other services’ in NAS, for instance, has been split into estimates for (i) Education, (ii) Health and Social Work, and (iii) Other Community, Social and Personal Services including Renting of Machinery and Business Services, and Private Household with Employed Persons. Before 2011-12, NAS provides estimates of factor incomes for registered manufacturing and unregistered manufacturing, but not for individual manufacturing industries. However, 2011-12 onwards NAS disaggregated the manufacturing sector in corporate sector and household sector. The NAS estimates of factor incomes for registered manufacturing and corporate sector have to be split into various manufacturing industries considered in the study (13 in number) using ASI data. The reported CE in NAS for registered manufacturing and corporate sector has been distributed into those 13 industries in proportion to the reported ASI data on emoluments for various industries. In a similar way, using ASI data, the estimate of OS for registered manufacturing and corporate sector has been distributed. Emoluments are subtracted from gross value added for various industries yielding capital income. The share of different industries in aggregate capital income of organized manufacturing indicated by the ASI data is used to split the estimate of OS for registered manufacturing and corporate sector reported in the NAS. The methodology applied for unregistered manufacturing and household sector is similar. The published results and unit level data of survey of unorganized manufacturing industries have been used for this purpose. The estimates of wage payments (to hired workers) in different industries have been used to split (proportionately) the estimate of CE in the NAS for aggregate unregistered manufacturing. The estimated wage payment is subtracted from the estimated value added to obtain an estimate of capital income and mixed income of the self-employed in various unorganized manufacturing industries. The estimate of MI provided in NAS for unregistered manufacturing and household sector has then been proportionately distributed across industries using the estimate of capital income and mixed income of the self-employed in various industries that could be formed on the basis of published results and unit level data of survey of unorganized manufacturing industries. Unlike the ASI data for organized manufacturing, the data for unorganized manufacturing enterprises are available for only select years. The proportions mentioned above could therefore be computed only for those select years (data for five rounds have been used; these are for 45th Round (1989-90), 51st Round (1994-95), 56th Round (2000-01), 62nd Round (2005-06), 67th round (2010-11) and 73rd Round (2015-16)). It has accordingly, been necessary to resort to interpolation/ extrapolation to obtain the relevant proportions for other years. Step 2: Splitting of MI into Labour Income and Capital Income As explained above, the income share of labour is computed as:  The derivation of the GVA series for different industries has been briefly explained in Chapter 2. The derivation of CE and MI series has been explained in step I above. Therefore, only the estimation method of ƞ needs to be described. The estimation of ƞ has been done with the help of NSS survey based estimates of employment of different categories of workers (number of persons and days of work) and wage rates (which has been described briefly in chapter 4) coupled with estimates of MI, basically obtained from the NAS. Two approaches have been taken to get an estimate of ƞ, and the labour income share series for different industries finally adopted in the study makes use of an average of the estimates of ƞ obtained by the two approaches. In the first approach, an estimate of labour income of self-employed workers has been made for each study industry for five years, 1983-84, 1987-88, 1993-94, 1999-00, 2004-05, 2009-10, 2011-12 and 2015-16 on the basis of the estimated number of self-employed, wage rate of self-employed and the number of days of work per week. The industry-wise estimates of number of self-employed, wage rate of self-employed and the number of days of work per week have been made from unit records of NSS employment-unemployment survey (major rounds), as explained in chapter 4 above. The estimates of the number of self-employed, wage rate of self-employed and the number of days of work per week provide an estimate of the annul labour income of self-employed workers which is divided by the mixed income of self-employed (derived from NAS) to get an estimate of ƞ. For five industries, the ratio in question has been computed and applied. For the other 22 industries, the ratio in question has been computed after clubbing the industries into 11 industry groups.33 In the latter case, a common ratio computed for group of industries has then been applied to constituent industries. The list of industries or industry groups for which ƞ has been estimated is given in table 7.2. In the second approach, the NSS data are used to compute the following ratio: the ratio of labour income of self-employed workers to the labour income of regular and casual workers. Let this be denoted by θ. Then, the estimate of CE provided in the NAS is multiplied by θ to obtain an estimate of the labour income component out of the MI reported in the NAS. The labour component of MI divided by total MI gives an estimate of ƞ. In case the estimated labour component of MI exceeds the estimate of MI, the estimate of ƞ has been taken as unity. Examining the estimates obtained by the first approach, it was found that the estimated labour income share out of mixed income varied significantly among the estimates for the seven years for which the ratio in question has been estimated. The estimates of ƞ obtained by the second approach has the problem that in a number of cases, the estimated labour component of MI exceeds the estimate of MI given in the NAS, and therefore ƞ is taken as one. The method finally adopted is as follows: (a) The average value of ƞ has been computed for each industry or industry group by taking the estimates for the years 1983-84, 1987-88, 1993-94, 1999-00, 2004-05, 2009-10, 2011-12 and 2015-16. This has been done separately for the estimates based on approach-1 and those based on approach-2. (b) The estimates of ƞ obtained for each industry or industry group by the two approaches have then been averaged. (c) Having obtained an estimate of ƞ, equation 6.1 given above has been applied to compute the labour income share. b) Construction of Factor Income Share Series in Gross output The income share of labour, capital and intermediate inputs in Gross output has been computed using the following steps:
The splitting of unorganized sector factor incomes into individual industries has been done using unorganized survey results. The proportions computed for 1983-84 has been applied for the period 1980-81 to 1983-84. While there were surveys of unorganized manufacturing enterprises in 1978-79 the survey results have not been used for estimation of factor incomes in different industries of the unorganized manufacturing sector. Chapter 8: Growth Accounting Methodology This chapter deals with the methodology of measurement of total factor productivity (TFP) growth for individual industries in the KLEMS framework and the aggregation from industry level productivity measures to measures for broad sectors and the economy as a whole. The methodology of analysis of sources of gross output growth at the individual industry level and sources of GVA (Gross Value Added) or GDP growth at the broad sector level and economy level will also be presented in this chapter 8.1 Methodology for Measuring Productivity Growth at the Industry level The production function Our measurement of TFP growth for different industries of the Indian economy is based on a gross output production function for each industry j:  Y is industry gross output, L is labour input, K is capital input and E, M and S are intermediate inputs-namely energy, material and services and T is an indicator of technology for industry j. All variables are indexed by time (t subscript is suppressed). There are several things to note about the production function - (1) all variables are aggregates of many components that have been discussed in the earlier report/chapters; (2) we assume that the industry production function is separable in these aggregates; (3) time (indicator of technology) enters the production function symmetrically and directly with inputs. An important feature of the gross output approach is the explicit role of intermediate inputs. In our study, we have considered three intermediate inputs - energy, material and services and this is important as we may find that intermediate inputs are the primary component of some industries outputs.34 Failure to quantify intermediate inputs leads us to miss both the role of key industries that produce intermediate inputs and the importance of intermediate inputs for the industries that use them. In order to estimate the production function at constant prices, the industry level price data is used for output, capital, labour and intermediate inputs, e.g., PYj; PLj, PKj; PEj. PMj, PSj. We assume that all industries face the same input price. The industry price of an input varies across industries due to compositional effects as industries expend different shares of their investment on each type of asset. The same is true for all inputs. Total Factor Productivity To estimate TFP growth, we begin with the fundamental accounting identity for each industry where the value of output equals the value of inputs. 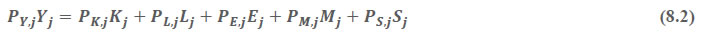 Under specific assumptions of constant returns to scale and competitive markets, we can define TFP growth as  Rearranging equation (8.3), yields the standard growth accounting decomposition of output growth into the contribution of each input and the TFP residual 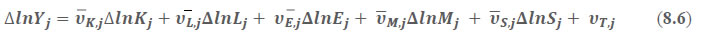 where the contribution of an input is defined as the product of the input’s growth rate and its two period average value share. We can further decompose the contribution of each input into a quantity and quality component. As discussed earlier, the quality component represents substitution between H components, while the quantity component represents the increases in each detailed input. Our extended decomposition of the sources of output growth is given as follows 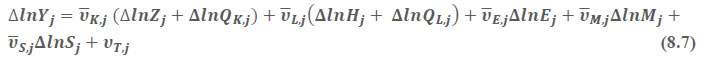 Where Z is the stock of industry capital, Qk is the capital quality, H is number of persons employed and Ql is the quality of labour. 8.2 Methodology for Aggregation across Industries In the analysis presented in the above section, gross value of output (GVO) is taken as the measure of output of an industry and TFP growth was estimated using the gross output function framework in which capital, labour, materials, energy and services are taken as five inputs (in the case of agriculture, land was included among inputs). The Törnqvist index is applied to estimate TFP growth for each year during 1980-81 to 2017-18, which yielded an index of TFP for each industry for that period, permitting estimation of trend growth rate in TFP for the period under study (1980-81 to 2017-18). The method of estimation of TFP growth for individual industries described in section 8.1 cannot be readily applied to a higher level of aggregation. The main problem is that gross value of output cannot be added across industries to generate a measure of output at a higher level of aggregation, say for the economy or of any of the broad sectors. It becomes necessary therefore to consider appropriate methods of aggregation across industries consistent with the gross output function specification of technology at the individual industry level. It is needless to say that one has to use the concept of value added to define an appropriate measure of output at the economy or broad sector level, but even here there are important issues of aggregation, i.e. how value added in different industries should be combined. A very useful discussion of the issues involved is found in Jorgenson et al. (2005). There are three approaches to estimating TFP growth at an aggregate level. This is discussed in detail in Jorgenson et al. (2005). The first approach is called aggregate production function approach. This approach assumes the existence of an aggregate production function (say, at the level of the economy or at the level of manufacturing or services sector). An essential condition is that the production function be separable in primary inputs. Let the production function for a particular industry be defined as:  where Y denotes gross output, X intermediate input (in turn a combination of materials, energy and services), K capital input, L labour input and T time (representing technology). Then, the concept of value added requires the existence of a value added function which in turn requires that the above production function be separable in K, L and T, i.e. the production function should take the following form:  In this equation, V (.) is the value added function. V denotes value added. Besides the condition of separability of the production function described above, a number of highly restrictive assumptions have to be made for the aggregate production function approach. These include: (a) the value added function is the same across all industries up to a scalar multiple, (b) the functions that aggregate heterogeneous types of labour and capital must be identical in all industries, and (c) each specific type of capital and labour receives the same price in all industries. With these assumptions made, real value added at the aggregate level becomes a simple addition of real value added in individual industries. In notation,  where Vi is value added in the ith industry and V is the aggregate value added. Given aggregate value added and somewhat similarly defined aggregate capital and labour input, TFP growth at the aggregate level can be computed. The second approach to aggregation is the aggregate production possibility frontier approach. It also needs the separability condition described in equations 8.8 and 8.9 above, as in the case of the aggregate production function approach. The main difference between the aggregate production function approach and the aggregate production possibility frontier approach is that the latter relaxes the assumption that all industries must face the same value added function. Thus, the price of value added is no longer assumed to be the same across industries. The implication is that the aggregate value added from the aggregate production possibility frontier is given by the Törnqvist index of the industry value added as:  In this equation, wi is the share of industry i in aggregate value added in nominal terms. Thus, defining PV,i as the price of value added in industry i and Vi as the real value added in industry i, the share in question may be defined as:  and the two period average is defined as:  Since each industry is subject to a production function separable in capital, labour and technology, as defined in equation 8.9, real gross output, real value of intermediate inputs and real value added of industry i in a particular year t should satisfy the following relationship:  In this equation, uV and uX are the shares of value added and intermediate inputs in the gross value of output in nominal terms. Given data on growth in gross output and growth in intermediate input of a particular industry, the above equation yields the growth in real value added of that industry. TFP growth from the aggregate production possibility frontier may be defined as follows:  In this equation K and L are aggregate capital input and labour input respectively, and vK and vL are value shares (or income shares) of capital and labour respectively. If one maintains the assumption that each specific type of capital and labour input has the same price in all industries, then each type of capital (labour) can be summed across industries and then a Törnqvist index can be constructed to yield aggregate capital (labour) input. Alternatively, different types of capital input can be combined using a Törnqvist index into total capital input used in an industry and then industry level growth in capital input can be combined with the help of a Törnqvist index to obtain growth in capital input at the aggregate level. In a similar manner, the growth in aggregate labour input can be computed. The third approach to measuring the TFP index at a higher level of aggregation is to apply direct aggregation to industry level estimates. This maintains the industry level production accounts as the fundamental building block and begins with industry level sources of growth. Of the three approaches described here, this is the least restrictive in terms of the assumptions involved. The following equation expresses the relationship between aggregate value added growth and the growth in capital and labour inputs and TFP in individual industries: 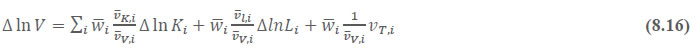 In this equation, vK is the value share of capital in gross output, vL is the value share of labour in gross output, vV is the share of value added in gross output, and wi is the share of industry i in aggregate value added in nominal terms. The bars indicate that the average of two periods, t and t-1, are to be taken. The last term in equation 8.16 is:  This is the Domar aggregation of TFP growth rates at individual industry level. Note that it is weighted average of industry level TFP growth rates. However, the weights add up to more than one. The data constructed for gross value added and gross output, labour input, capital inputs, intermediate inputs and factor income shares (Chapters 2,3,4,5,6 and 7 respectively), are used to estimate TFPG during the period 1980 to 2017. Labour input is measured using total person worked (see, Chapter 4 for the detailed discussion). The series on growth rate in capital services is taken from Chapter 5. 1 Timmer, M.P, Mahony, M. and van Ark, B. (2007). The EU KLEMS growth and productivity accounts: an overview. Mimeo University of Groningen & University of Birmingham, 2 Readers can refer to India KLEMS Data Manual Version 2013 for the data set released by RBI on its website in June 2014. 3 Basic price is the price receivable by the producer from the purchaser for a unit of a good or service produced as output, minus any tax payable, and plus any subsidy receivable, on that unit as a consequence of its production or sale. It excludes any transport charges invoiced separately by the producer. 4 From both aggregated 9 NAS sectors Gross Domestic Product by economic activity statement along with the disaggregated statements of these 9 NAS sectors. 5 The principal components of Manufacturing nec are Manufacturing of jewellery and related articles, Manufacture of musical instruments, Manufacture of sports goods, Manufacture of games and toys and other manufacturing. 6 Refer to Appendix A for details about all the employment and unemployment surveys conducted by NSSO in India. 7 Problems in using UPSS are: The UPSS seeks to place as many persons as possible under the category of employed by assigning priority to work; no single long-term activity status for many as they move between statuses over a long period of one year, and Usual status requires a recall over a whole year of what the person did, which is not easy for those who take whatever work opportunities they can find over the year or have prolonged spells out of the labour force. 8 This procedure has been advocated by NSSO itself and has been consistently adopted by almost all researchers. 9 A very lucid description of the same is given by Sivasubramonian (2004). 10 Appendix Table D provides the details about the Census Population, WFPR by UPSS, and persons employed in each of the EUS rounds used in the study. 11 The 66th round has not been used because of its inconsistency with the 61st and 68th round. Most economists consider it as an outlier. 12 Refer to Appendix Table C for data and sources for the EUS rounds (benchmark years). It gives the estimates of the four segments and the respective population for the major rounds which have been used to get the total employment by industry. 13 Aggregate input is measured as a translog index of its individual components. Then the corresponding index is a Törnqvist volume index (see Jorgenson, Gollop and Fraumeni 1987). For all aggregation of quantities, we use the Törnqvist quantity index, which is a discrete time approximation to a Divisia index. This aggregation approach uses annual moving weights based on averages of adjacent points in time. The advantage of the Törnqvist index is that it belongs to the preferred class of superlative indices (Diewert 1976). Moreover, it exactly replicates a translog model which is highly flexible, that is, a model where the aggregate is a linear and quadratic function of the components and time. 14 The assumption basically requires perfect competition in labour market, which does not exist in countries like India. It thus restricts the applicability of such a method in situations where there may be widespread monopsony power or bilateral monopoly within an industry. 15 EU KLEMS faces this problem by restricting the estimation of change in labour quality in some cases to only fifteen aggregate industries and assuming it to be same for sub-industries (Timmer, et al; 2010; p 118). 16 The index can also be described as “education” index, as only educational characteristic has been used in its computation. 17 In EU-KLEMS changes in labour quality has been measured by including employment class, gender, age and education (Timmer, op cit; p64) and only 3 categories of education defined as high skilled, medium skilled and low skilled have been taken. This concept of labour quality is refereed as ‘labour quality’ by Jorgenson. It is recognized (Timmer; op cit; p84) that the categorization may lead to biases in the aggregate quality adjustment if employment trends and wage share differ within categories. These education categories generally correspond to- up to Primary education, above Primary to Hr Secondary education and above Hr Sec or College education. Due to data limitations in India we have measured changes in labour quality only by changes in education profile of labour; hence can also be named as labour education index. Therefore, it became necessary to have a more detailed classification of education to capture the changes in skill quality of labour in India. 18 The educational categories in the 38th and 43rd round did not have a separate classification for Higher Secondary (Hr. Sec.) and was introduced for the first time in the 50th round. Hence the categories are not exactly comparable in the six rounds. For this reason, we combined the secondary and Higher Secondary categories into a category of Secondary to Higher Secondary. The labour composition index has been computed using five education categories namely- up to primary, primary, middle, secondary & higher secondary, and above higher secondary. 19 Appendix Table 4A.2 gives the education profile of persons employed by UPSS over major rounds. 20 In PLFS (2017-18), the earnings by self-employed are also provided, but for consistency with other rounds we have used the same procedure of Mincer equation even for this round. In EU KLEMS (Timmer, op cit; p 67) it is assumed that the earnings of the self-employed is equal to the earnings of ‘regular' employees. 21 The details of the function can be obtained from the Stata software and from Appendix 4A 22 Asset prices are used in the aggregation of capital stock. However, it is the price of the capital service that must be used in aggregating capital services (see Jorgenson and Griliches, 1967; Diewert, 1980) as it is the services delivered by capital goods that are used in the production process. Jorgenson and Griliches (1967) have shown that these two prices are related; the asset prices are the discounted value of all future capital services. They are not proportional though, as there are differences in replacement rates and capital gains among different capital assets. 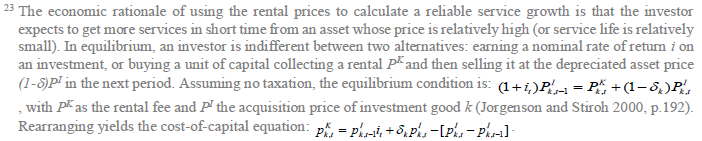 24 This version of the database does not make a distinction between ICT and non-ICT assets, as the industry level data on ICT assets are weak. An attempt to estimate aggregate economy level ICT capital can be found in Erumban and Das (2015). 25 See O’ Mahony and Timmer (2009) for a description of EU KLEMS database 26 This data is not publicly available. However, CSO has been kind to compile this data for the India-KLEMS project. 27 In some years transport equipment was provided as part of the machinery and equipment, categorized as ‘tools, transport equipment and other fixed assets. In such cases, we use transport/tools, transport and other fixed asset ratio in the nearest year to separate transport equipment. 28 This choice is driven by the fact that the first year of availability of ASI data is 1964-65. 29 National Accounts Statistics-Sources and Methods, Chapter 26, CSO (2007), 30 We do not intend to delve into the controversies over the use of internal vs. external rate of return in the context of productivity measurement. This database uses See Erumban (2008a and b) for a discussion on these issues. 31 Reserve Bank of India, Handbook of Indian Statistics, Annual volumes. 32 IOTT 2015-16 was published by Brookings India. 33 The estimation is done at group level rather than individual industries on the consideration that the group level estimates will be more reliable. 34 Consider, the semi conductor (SC) industry, which is a key input to the computer hardware industry. Much of the output is invisible at the aggregate level because semi conductor products are intermediate inputs to other industries rather than deliverables to final demand - consumption and investment goods. Moreover, SC plays a role in the improvements in quality and performance of other products like-computers, communication equipments and scientific instruments. Failure to account for them leads us to miss the role of key industries that produce intermediate inputs and importance of intermediate inputs for the industries that use them. (Jorgenson, Ho and Stiroh (2005), Productivity, volume 3). |
||||||||||||||||||||||||||||||||||||

ಭಾರತೀಯ ರಿಸರ್ವ್ ಬ್ಯಾಂಕ್ ಮೊಬೈಲ್ ಅಪ್ಲಿಕೇಶನ್ ಅನ್ನು ಇನ್ಸ್ಟಾಲ್ ಮಾಡಿ ಮತ್ತು ಇತ್ತೀಚಿನ ಸುದ್ದಿಗಳಿಗೆ ತ್ವರಿತ ಅಕ್ಸೆಸ್ ಪಡೆಯಿರಿ!
ನಮ್ಮ ಅಪ್ಲಿಕೇಶನ್ ಅನ್ನು ಸ್ಥಾಪಿಸಲು QR ಕೋಡ್ ಅನ್ನು ಸ್ಕ್ಯಾನ್ ಮಾಡಿ













